Einführung in Metadaten und Dokumentation
- Written by
- Daniel Schopper
- Published on
- July 8, 2022
- Tagged with
- Data management
Lernziele
- Den Nutzen und die Bedeutung von (guten) Metadaten für den Forschungsalltag erkennen
- Bestandteile von Metadaten unterscheiden können
- Metadaten auf Verlässlichkeit überprüfen können
Warum brauchen wir Metadaten?
Man stelle sich vor: Eine Forscherin arbeitet an einem Projektantrag zu einem Aspekt der lateinischen Grammatik. Als Arbeitsgrundlage benötigt sie ein digitales Corpus von Texten. Naheliegenderweise möchte sie sich nicht die Mühe machen und ein solches Corpus selbst aufbauen, sondern bestehende Texte wiederverwenden.
Sie macht sich daher auf die Suche nach digitalen Ressourcen, die sie für ihr Textcorpus heranziehen kann. Ihre Recherche im Internet ist erfolgreich und sie stößt auf eine interessante Textsammlung, aber beim Versuch, auf den Datensatz zuzugreifen, scheitert sie an einem Login-Formular. Bei einer anderen Ressource hat sie etwas mehr Glück und kann den Datensatz herunterladen. Aber welches Format hat nun diese Datei, die sie auf ihrem Rechner hat, und wie kann sie sie öffnen? In einem dritten Fall kann sie den Datensatz herunterladen und öffnen - aber dann stellt sich die Frage: wie wurden die Daten produziert? Sind sie vollständig? Nach welchen Richtlinien ist die Digitalisierung erfolgt und sind die Daten daher für ihre Forschung überhaupt aussagekräftig? Und nicht zuletzt: Bei der Veröffentlichung der Texte wurde keine Lizenz angegeben – darf sie den Datensatz also überhaupt für ihre Forschung und ggf. Publikation verwenden?
Diese und ähnliche basale Informationen den potentiellen Nutzer*innen zur Verfügung zu stellen ist eine von vielen Aufgaben von Metadaten. Eine vollständige Metadatenbeschreibung eines Datensatzes erlaubt die schnelle Beantwortung von Fragen wie z.B.:
- Sind die Daten für mich relevant?
- Darf ich die Daten überhaupt verwenden? Und wenn ja, unter welchen Bedingungen bzw. Einschränkungen?
- Sind die Daten stimmig? Stimmen die Methoden, die zur Datengenerierung verwendet wurden, überein?
- Wie kann ich den Inhalt der Daten lesen und verarbeiten? Und was brauche ich, um ihre Struktur zu verstehen?
Unsere Forscherin hat ihren Antrag schließlich abgeschlossen und mit Erfolg bei einem Fördergeber eingereicht: Das Projekt kann starten! Ihr Textcorpus nimmt Gestalt an und rasch finden sich andere Forscher*innen, die ihre Arbeit wiederverwenden möchten: Nun findet sie sich selbst in der Position, Metadaten zu ihrem Corpus erstellen zu müssen. Außerdem möchte der Fördergeber in einem Data Management Plan Auskunft darüber erhalten, wo die durch seine Mittel finanzierten Ergebnisse archiviert werden: Unsere Forscherin muss sich nun für ein mögliches Forschungsdatenrepositorium entscheiden und darüber informieren, welche Informationen in welchem Format das Respositorium für die Archivierung benötigt.
Fazit: Wir alle sind sowohl Nutzer*innen als auch Produzent*innen von Metadaten und brauchen für alle Schritte im Datenlebenszyklus grundlegende Kenntnisse, um Daten von anderen Projekten oder anderen Wissenschaftler*innen für unsere Forschung nachnutzen zu können bzw. mit anderen Personen an geteilten Daten zusammenarbeiten zu können.
Selbst zwischen Mitarbeiter*innen ein und desselben Projekts entfalten sich E-Mail-Unterhaltungen mit Fragen wie: “Wo liegt die letzte Version von Datei X und welche Software brauche ich, um sie öffnen zu können?” oder “Darf ich Datei Y aus dem Internet für … verwenden?” Auch die Übung zu den Grundlagen des Datenmanagementshat bereits deutlich gezeigt, weshalb Metadaten wichtig sind: Nur mit Metadaten sind die Daten, die wir in unseren Projekten herstellen, überhaupt verständlich und im Verlauf bzw. am Ende des Projekts auffindbar und wieder- / weiterverwendbar.
Was sind Metadaten? Eine Bestandsaufnahme
Aber was sind nun eigentlich Metadaten? Versuchen wir zunächst einmal eine Annäherung. Die einfache Antwort, die man häufig liest und die sich mit dem vorangegangen Beispiel deckt, lautet einfach:
Metadaten sind Daten über andere Daten.
Das ist prinzipiell nicht falsch. Es stellt sich allerdings die Frage, ob diese Definition den Kern in vollem Umfang trifft, gerade wenn wir über geisteswissenschaftliche Metadaten sprechen? Deswegen folgt nun ein kurzer induktiv erstellter Überblick, wo überall Metadaten vorkommen können. Denn “Metadaten sind überall”.
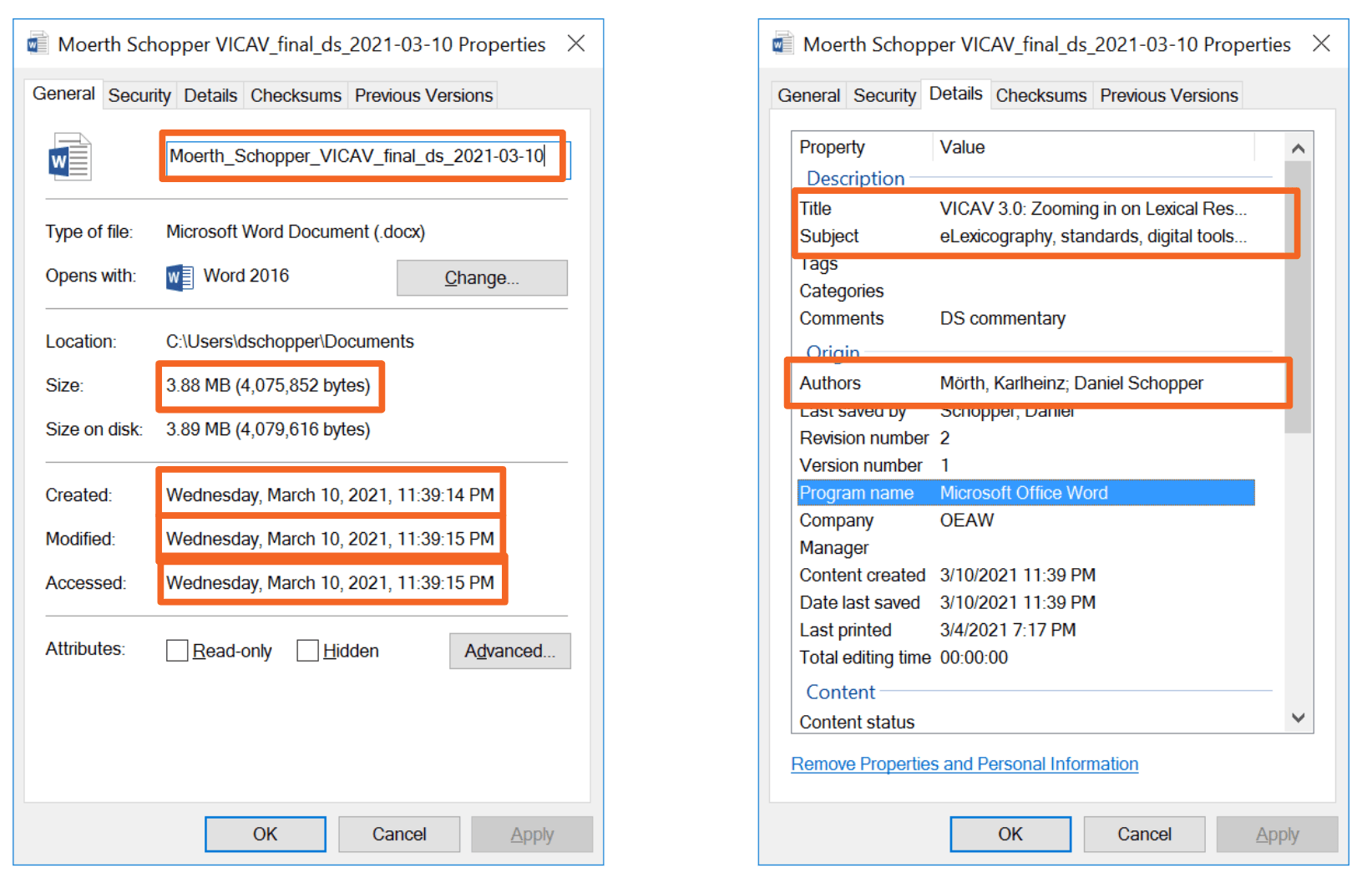
Abbildung 1: Metadaten über Dateien in den Eigenschaften einer Datei unter Windows. Bild: Daniel Schopper, CC-BY-4.0
Metadaten gibt es beispielsweise über die Daten auf unserem Computer. Hier haben wir es mit Dateien in einem Dateisystem zu tun. Diese Dateien liegen in bestimmten Ordnern, auf festgelegten physischen Laufwerken. Sie haben eine Größe, verschiedene Datumsangaben, Angaben zu Autor*innen, und sogar beschreibende Angaben wie den Titel, Thema usw. In der Regel beschreiben die Metadaten in unseren Dateisystemen Eigenschaften der physischen Datei und ihrer Entstehung bzw. Bearbeitung. Schlagwörter, Inhaltsangaben etc. beziehen sich hingegen auf den Inhalt, die semantische Ebene einer Datei wie z.B. eines Word-Dokuments.
Klar ersichtlich wird auch am obigen Beispiel: Metadaten in Computersystemen sind in aller Regel in “Feldern” aufgebaut, die einen Wert besitzen, der aus einem möglichen Wertebereich stammt: Im Feld “Created” darf nur eine Datums- und Zeitangabe stehen, in “Size” nur eine ganze Zahl, die – je nach Größenordnung – z.B. als Kilobyte, Megabyte oder Gigabyte angezeigt wird.

Abbildung 2: Metadaten in einem Digitalisat des retrodigitalisierten Nominalkatalogs der Universitätsbibliothek Wien. Bild: Daniel Schopper, CC-BY-4.0
Metadaten begegnen uns aber auch in ganz anderer Form, wie Abbildung 2 zeigt. Hierbei handelt es sich um ein Digitalisat des historischen Nominalkatalogs der Universitätsbibliothek Wien: Bibliotheken gehören zu jenen Institutionen, die sich am längsten mit der Organisation von Metadaten befassen. Einerseits beziehen sich die Angaben darin auf die einzelnen Exemplare eines Buches, um sie mithilfe ihrer Signaturen im Speicher auffindbar zu machen. Anderseits aber enthält das Katalogisat auch implizit Informationen über alle gleichartigen Exemplare dieser Publikation: Autor*in, Titel und Publikationsdatum sind keine Eigenschaften eines physischen Objekts, sondern der Abstraktion davon. Darüber hinaus finden wir in der Abbildung auch Informationen, die dabei unterstützen, sich im Metadatensatz selbst zurechtzufinden, z.B. Seitenzahlen oder der Kolumnentitel.
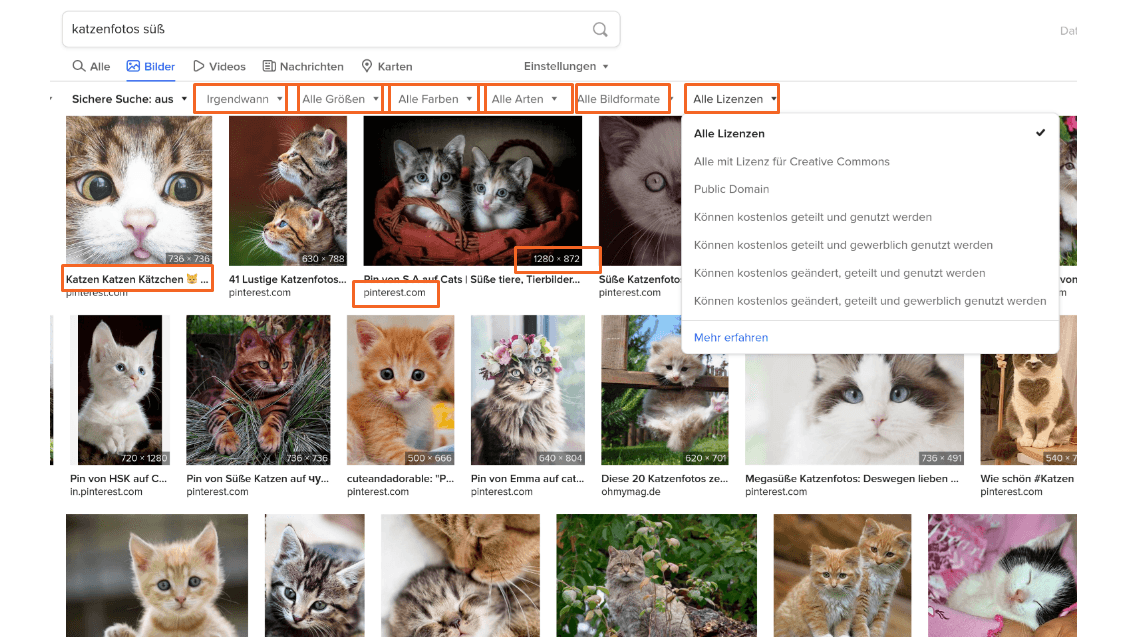
Abbildung 3: Metadaten in einer Bildersuche. Bild: Daniel Schopper, CC-BY-4.0
Aber auch wenn wir einfach eine Suchmaschine verwenden (siehe Abbildung 3), arbeiten wir in aller Regel mit Metadaten, um die Resultatliste nach bestimmten Parametern zu filtern: Im Fall der oben abgebildeten Bildersuche sind das technische Angaben (z.B. Aufnahmedatum, Größe, enthaltene Farben, Bildtypen, Bildformate), aber auch die Art der Lizenz oder die Herkunft der Daten. Im Normalfall werden die einzelnen Filter-Parameter nicht als Freitext eingeben, sondern aus einer Liste von möglichen Werten ausgewählt, sog. kontrollierten Vokabularien.
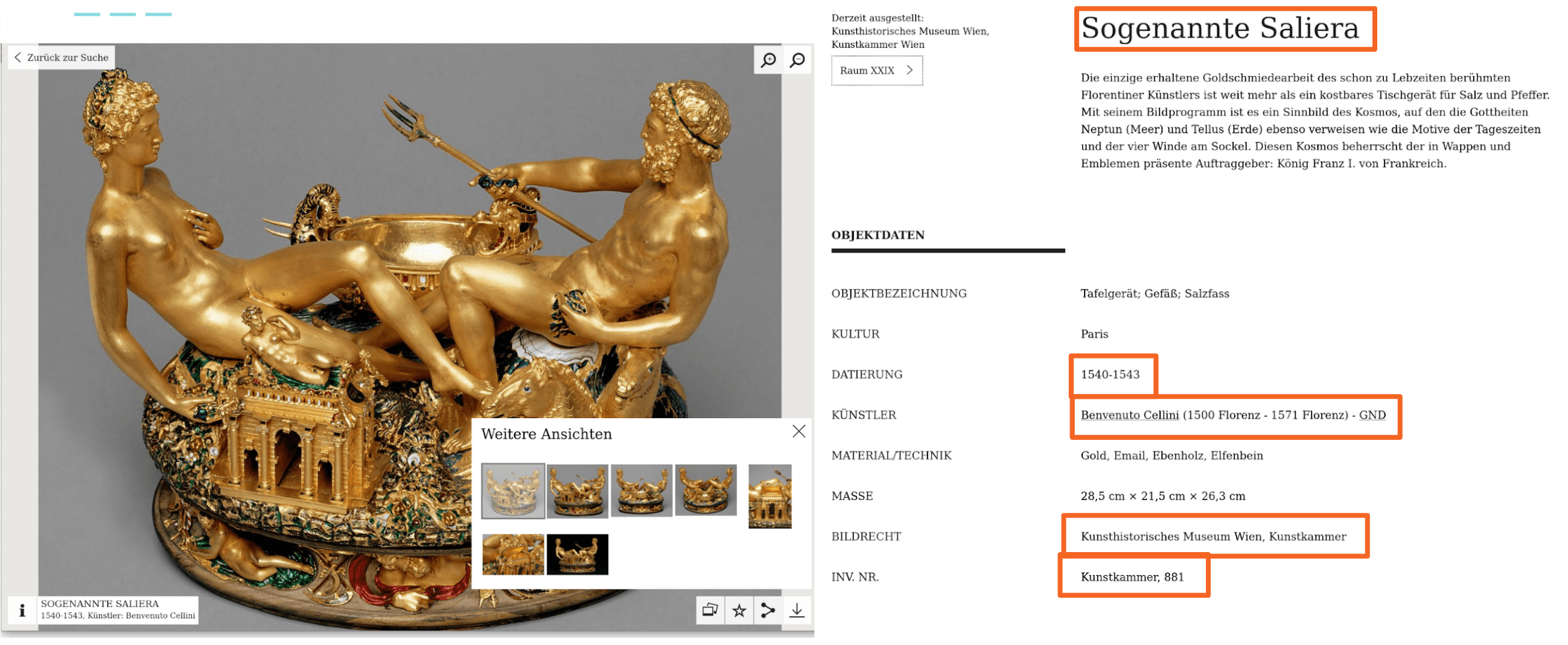
Abbildung 4: Metadaten in einer Detailansicht der “Cellini-Saliera” in der Online-Sammlung des Kunsthistorischen Museums. Screenshot: Daniel Schopper, CC-BY-4.0
Natürlich gibt es auch im Sektor des Kulturerbes Metadaten: Beispielsweise die sogenannten “Tombstone”-Informationen eines Objekts – ein Begriff, der ursprünglich von Beschreibungstexten im Museum kommt und sich in erweiterter Form auch in digitalen Sammlungen fortführt. Wie ein kleines Schildchen unterhalb eines Objektes oder Bildes in einem Museum bieten auch digitale Metadaten grundlegende Angaben wie z.B. Bezeichnung, Datierung oder relevante Personen.
Zusammenfassung
Allen Metadaten ist gemein, dass sie die Dinge, die sie beschreiben, aus verschiedenen Dimensionen erschließen. Dazu gehören in aller Regel:
- Benennungen (z.B. Kennzeichnung, Beschriftung, Titel, etc.)
- Zeitliche Dimension (Datums- und Zeitangaben)
- Größe / Umfang
- Geographische Dimension
- Verhältnis zu natürlichen Personen oder Institutionen / Körperschaften
- Inhaltliche Dimension (z.B. Verschlagwortung)
- Rechtliche Dimension (Besitzverhältnisse, Lizenzangaben)
Sprechen also Metadaten nur über Daten, wie die anfängliche Definition nahelegt? – Nein, bei genauerer Betrachtung greift diese Definition zu kurz. Denn in aller Regel beschreiben Metadaten nicht nur die digitalen Objekte, zu denen sie gehören, sondern auch zahlreiche Aspekte von all jenen realen und abstrakten “Dingen”, die ein digitales Objekt repräsentiert oder die mit ihm in Verbindung stehen.
Am Beispiel von digitalen Objekten aus dem Bereich des Kulturerbes wird das ganz deutlich: Wer mit der digitalen Repräsentation eines Kunstwerks arbeitet, interessiert sich in vielen Fällen besonders für jene Dimensionen, die gerade nicht durch die Fotografie oder den Scanvorgang erfasst werden können: beispielsweise die physischen Eigenschaften des digitalisierten Objekts oder die Ereignisse und Personen, die mit ihm in Verbindung stehen (z.B. Herstellung, Kauf/Verkauf). Dieses Wissen über die “realen” Objekte wird den digitalen Objekten beigegeben, um sie in ihrer Gesamtheit und möglichst umfänglich im digtalen Raum erfassen zu können.
Merke: Bei digitalen Objekten kann man grundsätzlich drei Ebenen unterscheiden:
- Physische Ebene: Digitale Objekte bestehen aus Bytes, die auf einem Datenträger “abgelegt sind”, haben also eine physische Komponente: Das können Dateien auf einem USB-Stick oder einer Festplatte sein, aber genauso Datenströme, die über ein Netzwerk zwischen Geräten ausgetauscht werden. Auf dieser Ebene werden die Eigenschaften der Objekte (und daher die “Werte” der Metadaten, die sie beschreiben) über die physische Ablage der Dateien bestimmt.
- Logische Ebene: Diese Ebene bezieht sich auf den inneren Aufbau der Daten, der es ermöglicht, dass sie von einer Software gelesen, angezeigt und manipuliert werden können. Beispiel: Damit verschiedene Textverarbeitungsprogramme das selbe Dokument öffnen können, muss ein gemeinsames Format definiert sein: ein Regelwerk, das Funktionsbereiche definiert und sie auf entsprechende Datenstrukturen abbildet. Dieses Regelwerk muss allen Programmen “bekannt” sein, die dieses Format lesen oder schreiben können sollen.
- ”Konzeptionelle” oder “semantische” Ebene: Dies ist die abstrakte Ebene des Dateiinhalts, die zunächst nur von Menschen durch Interpretation und “Hintergrundwissen” erschlossen werden kann: Was bildet ein Foto oder Scan ab?
Aufbau von Metadaten
Unabhängig vom technischen System oder Format, in welchem Metadaten gespeichert werden, ist der Aufbau von Metadaten stets derselbe. Um für die Nutzer und Ersteller verständlich und nützlich zu sein, müssen sich beide bei jedem Medatdatum auf folgende Informationen einigen:
- Welche Bedeutung hat das Metadatum? Welche Dimension (s.o.) bzw. welche Eigenschaft des beschriebenen Objektes deckt es ab? – Wie wir weiter unten sehen werden, kann die semantische Ebene einer Metadatumsdefintion mehr oder weniger eng gefasst sein. Außerdem bedarf es einer klaren Definition, denn “Feldnamen” allein können leicht mehrdeutig sein. (z.B.: Beschreibt das Metadatum “Titel” den Titel einer Publikation oder den (Adels-/Standes- etc.) Titel einer Person?)
- Hand in Hand mit der Frage der Beschreibungsdimension eines Metadatums geht die Definition, welche Werte bzw. Wertebereiche bei der Verwendung dieses Metadatums zulässig sein können, zumal die Semantik eines Metadatums hier Einschränkungen bedingt. So wird beispielsweise ein Metadatum, das sich auf ein Datum bezieht, ein standardisiertes Datumsformat wie ISO 8601 als Wertebereich festlegen.
- Und nicht zuletzt müssen Metadaten in einem Computersystem gespeichert werden, um benützbar zu werden. Hier stellt sich die grundlegende Frage: Auf welche Art und Weise und unter Verwendung welcher Zeichen werden die Informationen des Metadatums in einem Computersystem repräsentiert? Sinnvollerweise ist die Definition eines Metadatums von der tatsächlichen Art, der Speicherung – der syntaktischen Ebene – unabhängig. Dementsprechend gibt es oftmals mehrere syntaktische Varianten eines und desselben Metadatums, die sich nicht in ihrer Semantik, aber sehr wohl in ihrem Basisdatenmodell (z.B. RDF oder XML, s.u.) und den durch sie bedingten syntaktischen Regeln unterscheiden.
Um ein digitales Objekt beschreiben zu können, benötigt man mehr als ein einzelnes Metadatum, sondern ein ganzes Metadaten-Schema oder Metadaten-Vokabular. In diesem bewegen sich die Definitionen von Metadaten-Elementen innerhalb eines gemeinsamen Metadatenschemas immer auch im Rahmen eines gemeinsamen abstrakten Modells, das die verschiedenen Metadaten-Elemente zu einem homogenen Ganzen verbindet.
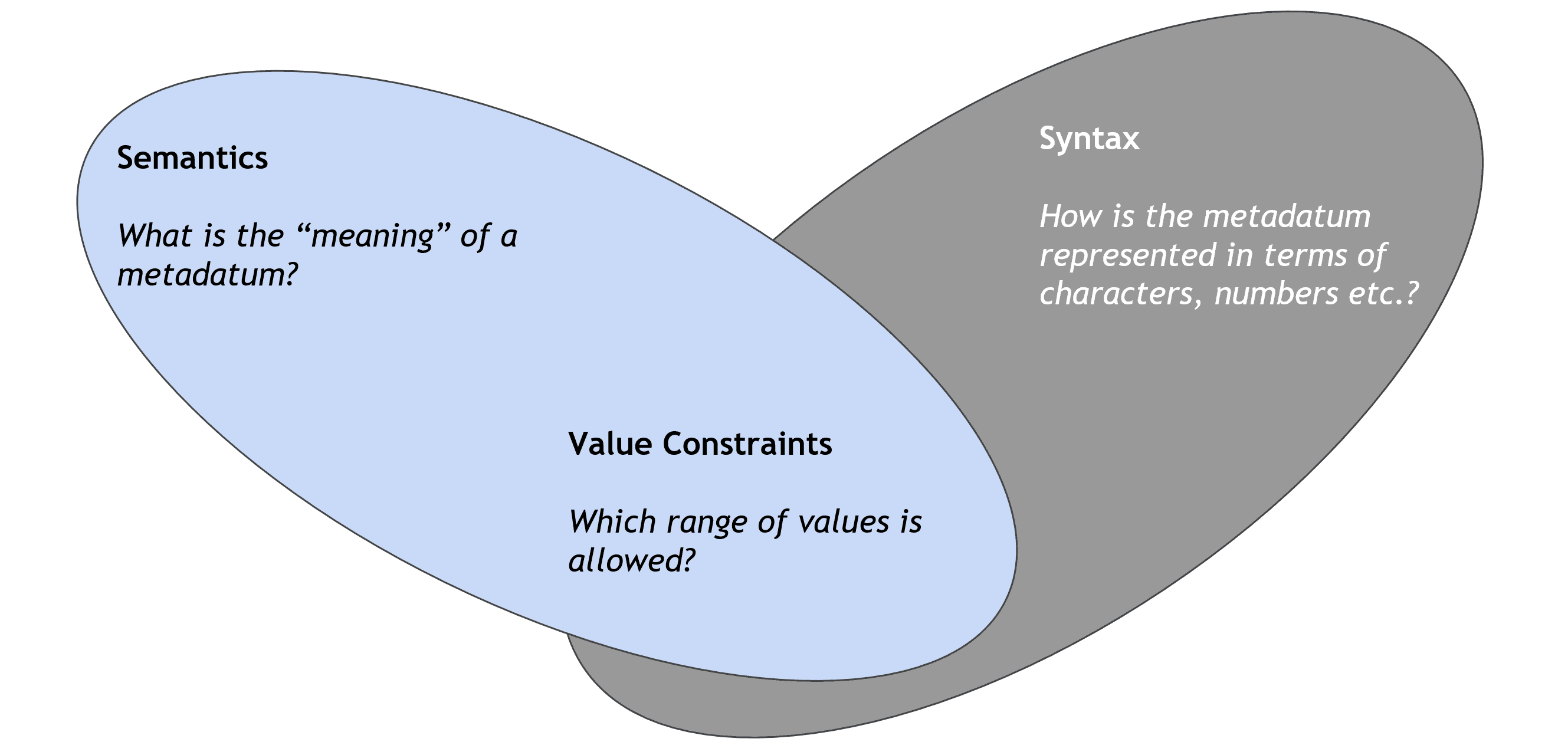
Abbildung 4: Struktur von Metadaten. Grafik: Daniel Schopper, CC-0
Anhand der sukzessiven Entwicklung des “Dublin Core”-Standards lassen sich diese drei Ebenen gut illustrieren:
Exkurs: Struktur von Metadaten anhand von Dublin Core (vgl. Pollin 2021)
Als in den frühen 1990er Jahren deutlich wurde, dass dem massiven Zuwachs an Informationen im noch vergleichsweise jungen Internet mit den traditionellen Strategien von Katalogisierung und Informationsgewinnung an Bibliotheken nicht beizukommen war, wurde 1995 nach einem Workshop am Online Computer Library Center (OCLC) in Dublin (Ohio) das Dublin Core Metadata Element Set (DCMES) präsentiert und in einer Reihe von offiziellen Standards publiziert: Dabei handelte es sich um eine Sammlung der 15 am weitesten verbreiteten Eigenschaften von Ressourcen, die so allgemein gehalten waren, dass sie für die Beschreibung von vielerlei digitalen und analogen Objekten (Webseiten, Büchern, Liedern, Bildern etc.) gleichermaßen nützlich sein würden. Ziel war eine abstrakte Definition der Eigenschaften ohne Vorgabe, wie diese in einem technischen System repräsentiert werden sollten: Die syntaktische Ebene wurde bewusst offen gelassen.
Eines der DCMES Elemente war “Datum” und wurde definiert als “Zeitpunkt oder -abschnitt, der in Verbindung mit einem Ereignis im Lebenszyklus einer Ressource steht.” (DMCI Usage Board 2020; übers. v. Daniel Schopper) Rasch war deutlich, dass diese Definition (und damit die semantische Ebene dieses Metadatums) zu lose definiert war, um in der Praxis nützlich zu sein. Daher wurden im Jahr 2003 mit Qualified Dublin Core die Elemente des DCMES um “Qualifikatoren” verfeinert (vgl. DCMI Qualifiers (2000-07-11)), die die möglichen Bedeutungen von “Datum” weiter unterteilten. Das Metadatum erhielt dadurch verschiedene Unterbedeutungen (“Element refinements”) wie z.B. “Created” (“erzeugt am …”), “available” (“verfügbar ab …”) oder “Issued” (“herausgegeben am …”).
Parallel dazu wurden Werte bzw. -Wertebereiche definiert, die für die verschiedene Eigenschaften zulässig waren: Als Standardformat eines Datums wurde beispielsweise die Notation “YYYY-MM-TT” gesetzt. In anderen Fällen wurden geschlossene Listen von möglichen Werten (sog. kontrollierte Vokabularien) festgelegt (beispielsweise für die Angabe der Sprache oder des Typs einer Ressource), sodass die Austauschfähigkeit von Dublin Core-Daten erhöht wurde.
Über die Jahre hinweg wurde die konkrete Syntax, in der die Dublin Core Elemente verwendet werden können, offen gelassen: Die DC Elemente wurden und werden direkt in HTML-Seiten integriert, in XML-Schemata (s.u.) oder mithilfe von RDF als Linked Data publiziert. Allen syntaktischen Repräsentationen liegt jedoch das Dublin Core Abstract Model zugrunde, das dafür sorgt, dass die verschiedenen syntaktischen Repräsentationen von Dublin Core trotz ihrer unterschiedlichen Erscheinungsform miteinander kompatibel sind.
Vokabularien und Normdaten
Wenn Metadaten von Suchmaschinen aggregiert oder zwischen Systemen bzw. Benutzern ausgetauscht werden sollen bzw. große Datenmengen anhand bestimmter Kriterien gefiltert werden sollen, sind in aller Regel kontrollierte Vokabularien im Spiel. Als ein augenscheinliches Beispiel kann der Bibliothekskatalog der ÖAW herangezogen werden: In diesem werden verschiedene Bestände (Bibliotheksbestand, Datenbanken, elektronische Ressourcen) in einem gemeinsamen Suchinterface zusammengefasst. Jeder Datenbestand folgt einem eigenen Metadatenschema mit eigenen Wertebereichen (s.o.). Um es zu ermöglichen, dass eine Menge von Suchresultaten anhand des Metadatums “Format” gefiltert werden kann, müssen die verschiedene Werte auf eine gemeinsame Liste von möglichen Werten homogenisiert (“gemappt”) werden, deren Bedeutung in etwa gleich ist.
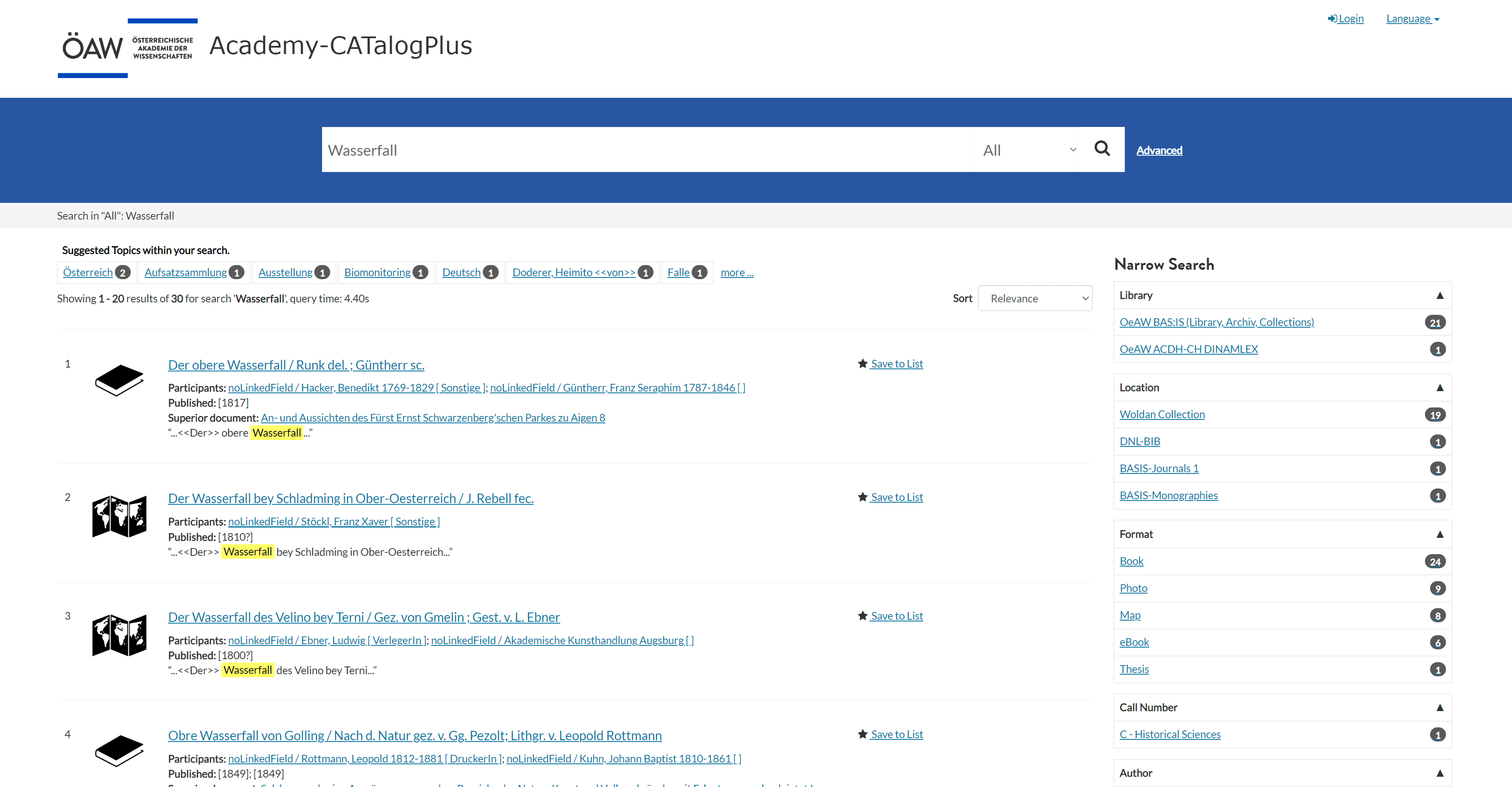
Abbildung 5: Katalog von Bibliothek und Archiv der ÖAW. Bild: Daniel Schopper, CC-BY-4.0
Zu diesem Zweck wird ein Vokabular erstellt, dessen einzelne Einträge (Terme) klar definiert sind und dessen Einträge untereinander bzw. zu anderen Vokabularien in Verbindung gesetzt werden können.
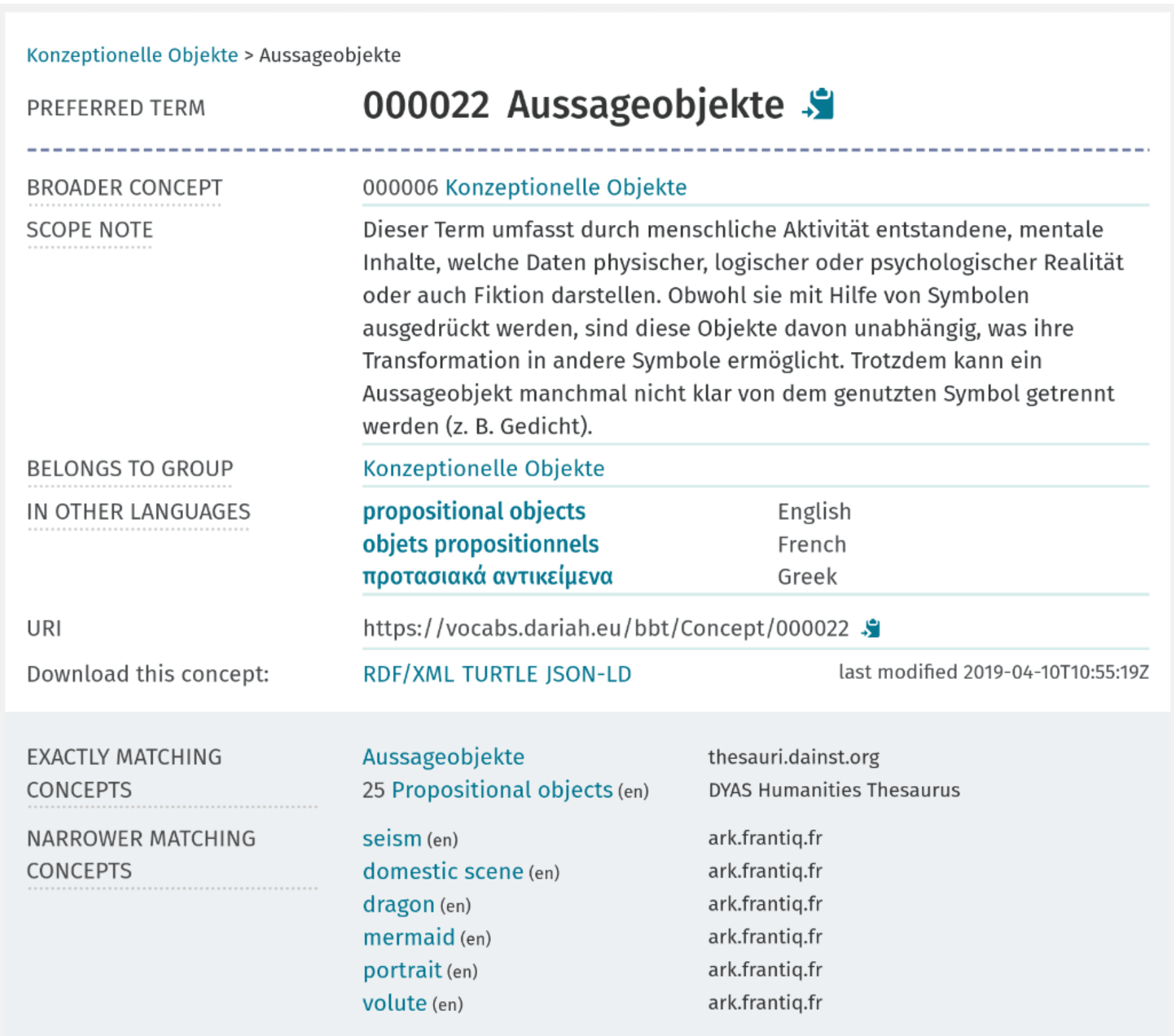
Abbildung 7: Screenshot des Konzepts “Aussageobjekte” aus dem DARIAH BBT. Bild: Daniel Schopper, CC-BY-4.0
Häufig werden Vokabularien im Bereich der Metadaten mit SKOS - Simple Knowledge Organization – erstellt, das die wichtigsten semantischen Verbindungen zwischen Termen bereitstellt. So werden ähnliche Terme mit der Relation skos:closeMatch verbunden; gleiche Terme mit skos:exactMatch.
Werden Vokabularien publiziert können andere Personen und Projekte die dort verwendeten Definitionen aufgreifen und so ihre Daten auf einer konzeptionellen Ebene miteinander kompatibel machen. Bekannte Beispiele für häufig genutzte Vokabularien sind beispielsweise der Getty AAT (Art & Architecture Thesaurus) oder DARIAH BBT (Backbone Thesaurus).

Abbildung 6: Varianten in der Schreibweise von Arthur Schnitzler in der DNB. Bild: Daniel Schopper, CC-BY-4.0
Ähnlich wie Konzepte können auch die Namen von Personen, Orten und Körperschaften ambig, also mehrdeutig sein. Gerade bei der Aggregation (Sammlung) von Metadaten – wie etwa im oben genannten Bibliothekskatalog – ist die Identifikation von Einzelpersonen oder einzelnen Arbeiten durch eine ein-eindeutige Schreibweise und/oder einen alphanumerischen Identifikator zentral. Auch hier hat das Bibliothekswesen bereits viel “Vorarbeit” geleistet. Hervorzuheben sind hier beispielsweise die Normdaten, auf Englisch “authority control files”. Beispiele sind hier Gemeinsame Normdatei (GND), Library of Congress Subject Headings (LCSH), oder Virtual International Authority File (VIAF). Diese kommen aus dem Bereich der Bibliothekskataloge, finden aber zunehmend auch im semantischen Web Anwendung. In Bibliothekskatalogen finden sich unterschiedlichste Namensschreibungen, Fehlschreibungen, Pseudonyme, unterschiedliche Sprachen. Um diese Ansetzungsformen alle auf eine einzige Identität zusammenzubringen, wird eine autoritative Form als Normdatum angesetzt. Dies kann in Form einer eindeutigen Namensansetzung sein, in Form einer innerhalb eines Normdatensatzes eindeutigen Nummer, oder – wie es nun im Semantic Web der Fall ist, in Form einer URI-Adresse. Dies gibt es für Personen, aber auch in generalisierter Form für Orte, Themengebiete oder aber generelle Terminologien, die auch aus dem Bibliotheksbereich hinaus gehen. Beispiele für generische Ressourcen sind z.B. GeoNames (Ortsnamen) oder auch Wikidata, welche Identifikatoren für die unterschiedlichsten Dinge, Konzepte, zeitlichen Ereignisse etc. vergibt.
Typen von Metadaten
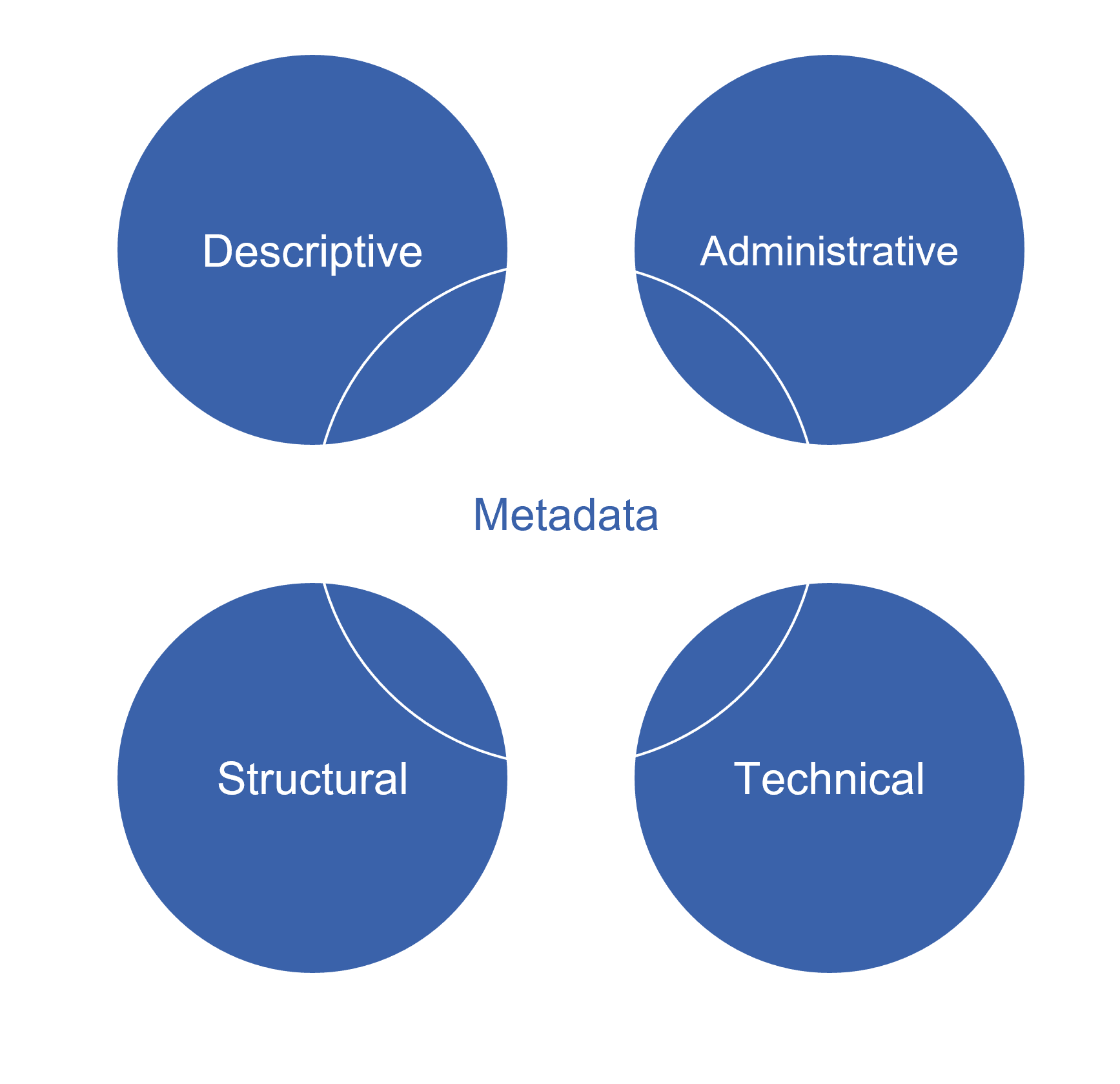
Abbildung 8: Metadatentypen. Grafik von Daniel Schopper, CC-BY-4.0
Die Literatur unterscheidet zumeist zwischen vier Gruppen von Metadaten:
- deskriptive Metadaten, welche die Daten an sich beschreiben.
- administrative Metadaten, die auf das Handling, die unterliegenden Prozesse und organisatorische Aspekte der Daten, ihrer Generierung, Verarbeitung oder Nachnutzung eingehen.
- strukturelle Metadaten, die die interne Struktur der Metadaten beschreiben.
- technische Metadaten, die Aussagen über die technische Repräsentation und Beschaffenheit eines digitalen Objekts treffen.
Zusätzlich könnte man als fünfte Dimension die Archivmetadaten unterscheiden, die der Autor für diese Übersicht aber unter die vier genannten Hauptgruppen subsumiert.
Diese vier Gruppen wollen wir uns nun genauer ansehen. Welche Fragen über die Daten werden dort beantwortet?
Deskriptive Metadaten umfassen vereinfacht gesagt das, was wir oft mit bibliographischen Metadaten ausdrücken. Diese sind letztendlich eine Identifikation und Beschreibung dessen, was wir sehen. Sie beschreiben also, um was es sich bei den spezifischen Daten handelt. Dies umfasst beispielsweise:
- Wie wird das Objekt / Datum genannt?
- Wer war in dessen Erstellung involviert?
- Wann wurde es publiziert?
- Worum geht es? - Dies umfasst inhaltliche Aspekte wie Themen, Schlagwörter etc.
- Wie ist die Erscheinungsform? - Diese kann abhängig vom Objekt sehr unterschiedlich sein. Beispiele sind Sprache, Farbe, Seitenzahlen (bei Printprodukten), etc.
Administrative Metadaten beschreiben die Einbettung in prozedurale und organisatorische Aspekte. Letztendlich geht es darum, wie die Daten behandelt werden.
-
Wo sind die Daten auffindbar?
-
Wer darf die Daten unter welchen Konditionen verwenden?
- Wer hat z.B. in einem größeren Projekt, in dem jeder nur bestimmte Teilbereiche eines Datenbestands bearbeiten darf und soll, die Bearbeitungsrechte?
-
Was ist der Status der Daten innerhalb ihres Lebenszyklus?
-
Wie wurden die Daten bisher verarbeitet?
- Was ist die Geschichte des Datenobjekts?
- Wurde es in ein Repositorium aufgenommen?
- Welche Bearbeitungs/Verarbeitungsschritte wurden vor der Aufnahme in ein Archiv vorgenommen (wichtig bei Archivmetadaten)?
-
Wo ist die Quelle der Daten (wo kommen sie her)? (Provenienz) - Daten werden wiederverwendet und nachgenutzt. Gerade dafür ist es wichtig die Herkunft der Daten klar zu dokumentieren.
Strukturelle Metadaten beschreiben wie Daten sich zusammensetzen.
- Wie sind Objekte intern strukturiert? - Wenn wir das Beispiel eines Buches hernehmen, so könnte man sagen, das Buch besteht aus einer Anzahl von Seiten oder aus Kapiteln. Die interne Struktur ist hier eine physischen Datenstruktur die sich dann beispielsweise in einer Ordnerstruktur abbildet.
- In welcher Beziehung stehen die Daten oder Objekte zu anderen Daten? - Sind sie beispielsweise Teil einer Kollektion oder eines größeren Zusammenhangs? Gibt es andere Versionen oder Vorversionen dieser Daten oder dieses Objekts an einem anderen Speicherort?
Technische Metadaten beschreiben wie ein Objekt aus technischer Sicht beschaffen ist, damit ein Computer dieses lesen kann. Dazu gehören beispielsweise
- Dateiformat
- Enkodierung – Also beispielsweise welches Zeichenformat wurde für die Kodierung eines Textes verwendet?
- Aufnahmetechnologie – Ein klassisches technisches Metadatum beispielsweise aus Fotokameras ist die Information wie ein Digitalisat aufgenommen wurde.
- Sampling / Auflösung - Dies beschreibt, wie genau die Übersetzung vom Analogen ins Digitale war. Sample-Raten bei Audio oder die Auflösung bei Bildern sind Beispiele.
Metadaten-Syntax
Im Hinblick auf die Syntax von Metadaten gibt es unterschiedliche Varianten, wie diese kodiert oder abgebildet werden können.
- unstrukturierte Metadaten - z.B. eine README-Datei. Diese ist zwar menschenlesbar und hoffentlich für Menschen verständlich verfasst aber nicht maschinenlesbar. Insofern lässt sie sich nicht ohne zusätzlichen Aufwand von einem Computer auswerten.
- semi-strukturierte Daten – z.B. XML oder JSON. Auf diese Form der Syntax werden wir in diesem Kapitel noch näher eingehen.
- Strukturierte Metadaten – z.B. tabellarische Informationen sowie RDF (XML, Turtle (TTL), JSON-LD). Hier steht die Struktur im Vordergrund.
Metadaten können entweder in die Daten oder digitalen Objekte, die sie beschreiben, eingebettet oder eigenständig (self-contained) sein, also in einer separaten Datei abgespeichert werden die neben den jeweiligen digitalen Objekten existiert. Beide Varianten haben ihre Vor- und Nachteile. Eingebettete Metadaten können - banal gesagt – nicht verloren gehen. Wenn sie in einer separaten Datei abgespeichert werden, sind sie ggf. leichter bearbeitbar und leichter zugänglich.
Im Folgenden werden kurz die unterschiedlichen syntaktischen Varianten beleuchtet, um Einsteiger*innen in die Materie einen grundlegenden Einblick in das Thema zu geben.
XML
Eines der wichtigsten Datenformate in der (kurzen) Geschichte der Metadaten im informationstechnischen Sinne ist sicherlich XML. Viele Metadatenschemata bauen auf dieses grundlegende Format auf. XML steht für eXtensible Markup Language – ein Webstandard, der vom World Wide Web Consortium entwickelt und 1998 erstmals als Empfehlung veröffentlicht wurde. Es ist ein Regelwerk wie man Vokabularien oder Schemata beschreiben kann. Es definiert eine Reihe von syntaktischen Regeln anhand derer man reine Textdokumente strukturieren kann, um sie danach menschen- und maschinenlesbar verwenden zu können.
Ein einfaches, fiktives Beispiel:
<absatz>
<zeile nummer="001">Dies ist eine <stichwort>Einleitung</stichwort> zu <format>XML</format>.</zeile>
</absatz>
Wenn wir einen Absatz in XML kodieren wollen, so können wir dies mit sogenannten Tags machen. Die grundsätzliche Regel ist, dass es immer einen Start- und einen End-Tag gibt, die den Inhalt umschließen. Spitzklammern markieren einen Tag, z.B. <paragraph> in diesem Fall. Der End-Tag wird mit einem Schrägstrich vor dem Tag-Namen markiert - </paragraph>. Durch die Start- und End-Tags werden Informationseinheiten klar abgegrenzt und diese sind zudem streng hierarchisch ineinander verschachtelt. XML zeichnet sich gegenüber anderen technischen Datenmodellen dadurch aus, dass es sowohl dokumentenorientiert als auch datenorientiert verwendet werden kann. Ein Dokument hat eine Reihenfolge von oben nach unten, was bei anderen Datenstrukturen nicht der Fall ist. Zudem ist XML eine Markup-Sprache, was es ermöglicht Text um zusätzliche Informationen anzureichern.
JSON
Ein weiteres Datenformat ist JSON (JavaScript Object Notation). Dieses Format kommt aus der Programmierung, und ist eigentlich ein Subset der Programmiersprache JavaScript. JSON ist genauso hierarchisch aber einfacher aufgebaut als XML. Es ist wie XML ein reines Textformat, das vor allem für datenorientierte Applikationen angewendet wird. Die Syntax besteht aus sogenannten “key-value pairs”. Das heißt, es gibt jeweils einen Schlüssel bzw. ein Label und einen Wert dazu. Diese Wertepaare können auch ineinander verschachtelt sein. Das Format ist entsprechend für einen Computer einfach zu verarbeiten, aber kennt die Mischung zwischen Freitext und Zusatzinformation nicht.
Hier ein Beispiel der Kodierung der bei XML eingeführten Absatzstruktur in JSON:
{
"type": "paragraph",
"number": 1,
"content": [
{
"type": "line",
"number": 1,
"content": "This is an introduction to JSON.",
"keywords": ["introduction"]
}
]
}
RDF
Der dritte wichtige Standard in dem Zusammenhang ist RDF (Resource Description Framework, W3C Consortium). RDF ist die Grundsäule des Semantic Web sowie Linked Open Data und ist von der Datenstruktur her vielleicht sogar die intuitivste Form. Die Datenstruktur basiert auf sogenannten Triples. Diese sind wie Aussagesätze mit einem Subjekt, einem Prädikat und einem Objekt strukturiert. Jede Entität innerhalb dieser Aussagen ist über eine URI (Unified Resource Identifier, also eine Art Webadresse) eindeutig identifiziert, sodass immer klar ist, worüber eine Aussage getroffen wird.
Mittels dieser sehr einfachen Aussagen-Struktur kann man dann immer weitere Kreise an Aussagen ziehen. Letztendlich stellen diese Aussagen gerichtete Graphen dar, die bestimmte Entitäten miteinander in Beziehung setzen.

Abbildung 9: Aufbau und Beispiel von RDF in den ARCHE Metadaten. Bild: Daniel Schopper, CC-BY-4.0
Das in Abbildung 9 gezeigte kurze Beispiel aus den ARCHE-Metadaten zeigt die Struktur sehr schön:
Wir haben zum einen ein Objekt aus der Arche mit einer bestimmten Nummer (111841) als Subjekt. arche: ist ein sog. Präfix, also ein Platzhalter für einen Identifikator, der durch die Abkürzung besser lesbar wird.
Dieses Objekt hat mehrere Eigenschaften, die in den Prädikaten definiert werden:
- Einen Titel (
hasTitle) - Einen Typ (
type) - Eine bestimmte Anzahl an Objekten (
hasNumberOfItems) - Einen bestimmten Identifikator (
hasIdentifier)
Als Objekt wird entweder ein String-Wert – also eine Zeichenfolge – zugewiesen oder ein Verweis auf das nächste Objekt, wodurch Objektverkettungen oder -bezüge hergestellt werden.
Für die Ausformung dieser Aussagen in RDF gibt es unterschiedliche Syntax-Formen: XML, JSON-LD oder TTL (Turtle) - letztere ist jene auch für Menschen gut lesbare konzise Schreibweise, die auch im obigen Beispiel verwendet wurde.
Persistente Identifikatoren
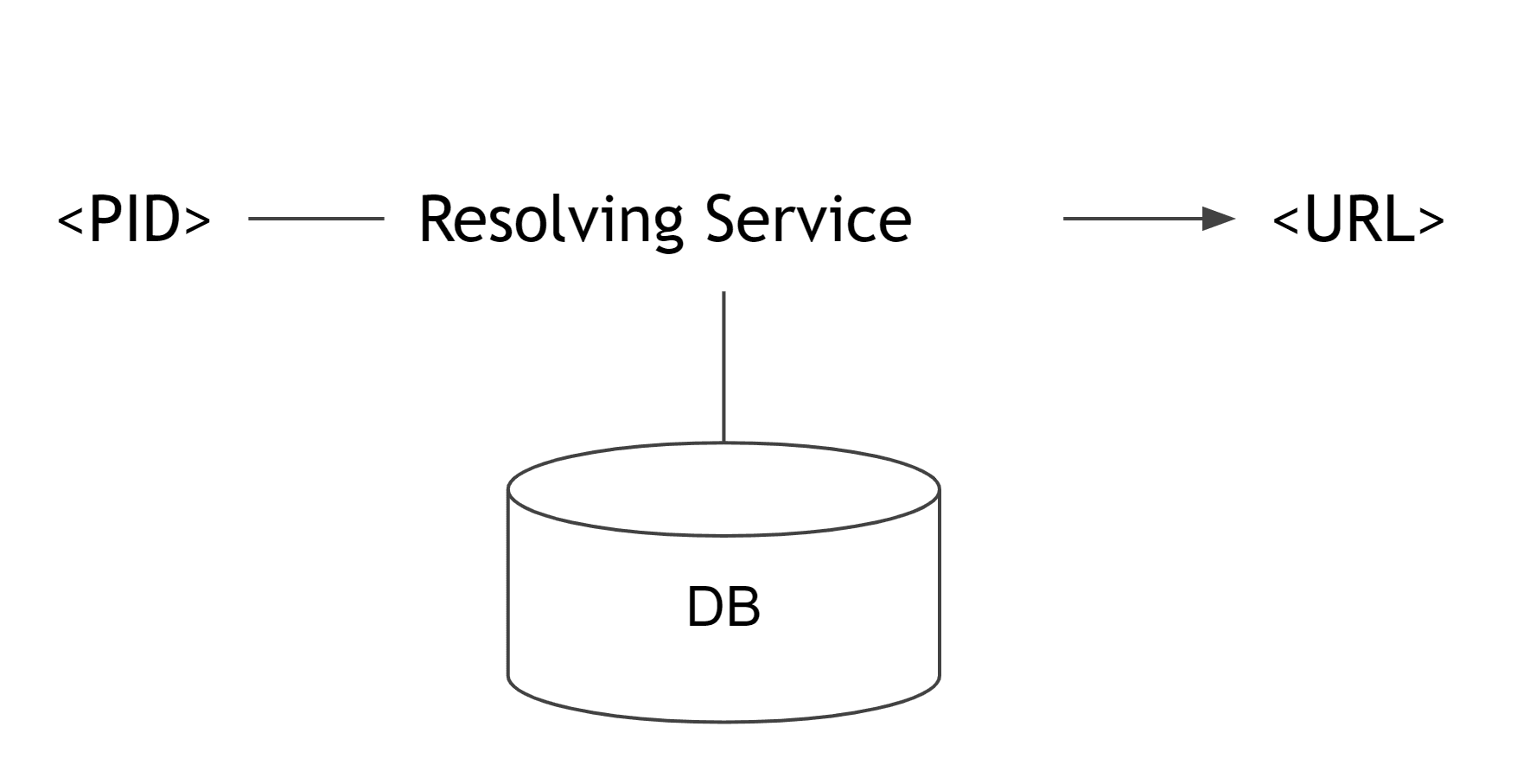
Abbildung 10: Schematische Beschreibung eines Persistent Identifiers. Bild: Daniel Schopper, CC-BY-4.0
Im Hinblick auf die technische Infrastruktur ist die Verwendung von Persistenten Identifkatoren zentral für stabile Metadaten und die langfristige Auffindbarkeit von Ressourcen.
In vielen Fällen sind Adressen im Netz instabil und nicht dauerhaft. Das heißt Adressen können sich ändern oder umziehen, Institutionen können aufgelöst werden etc. Metadaten sollten aber stabil referenziert werden. Um dieser Flüchtigkeit der Adressen entgegenzuwirken, gibt es unterschiedliche Arten von persistenten Identifikatoren, die im Prinzip alle über eine Art von indirekter Adressierung funktionieren. In dem Falle bleibt der persistente Identifikator stabil, aber es wird ein Service zwischengeschaltet, das über eine Adressdatenbank die aktuelle “flüchtige” Adressierung des Objekts im Web auflöst (Resolving Service). Ein Beispiel ist DOI, das aus dem Bereich des Bibliothekswesens und der Publikationen bekannt sein dürfte. Es gibt aber noch andere Systeme wie handle.net, URN, ARK, PURL.