Corpus Query Language im Austrian Media Corpus
- Written by
- Hannes Pirker
- Published on
- April 27, 2023
- Tagged with
- Corpus
Lernziele
- das Austrian Media Corpus (amc) kennenlernen
- einen Einblick in die Funktionalität der Korpussuchmaschine Sketch/NoSketch Engine erhalten
- einfache Suchabfragen im amc durchführen
- mit der Corpus-Query-Language (CQL) komplexere Suchabfragen formulieren
Einführung
Das Austrian Media Corpus (amc)
Das Austrian Media Corpus (amc) ist eines der größten Textkorpora in deutscher Sprache. In ihm sind Texte der österreichischen Printmedienlandschaft der letzten Jahrezehnte versammelt. Der Inhalt des amc kann mit dem Schlagwort “journalistische Prosa” zusammengefasst werden: er umfasst Komplettausgaben von Zeitungen und Zeitschriften, Agenturmeldungen der Austria Presse Agentur (APA) sowie Transkripte von TV-Produktionen (vorwiegend von Nachrichtensendungen).
Das amc kann auf Anfrage genutzt werden, allerdings ausschließlich für Zwecke der wissenschaftlichen Forschung und Lehre und nur für die Untersuchung sprachwissenschaftlicher Fragestellungen. Ermöglicht wird das amc durch eine Kooperation zwischen der Austria Presse Agentur (APA) und der Österreichischen Akademie der Wissenschaften (ÖAW), konkret dem Austrian Centre for DigitalHumanities and Cultural Heritage (ACDH-CH). Die APA sammelt die Textproduktion der Printmedien und stellt diese dem ACDH-CH zur Verfügung.
Das amc wird jährlich am Jahresanfang um die Publikationen des soeben abgelaufenen Jahres aktualisiert, d.h. der aktuelle Datenbestand des amc reicht jeweils bis zum Ende des Vorjahrs.
Mit dem amc arbeiten
Das ACDH-CH ergänzt die Texte, die von der APA zur Verfügung gestellt wurden, mithilfe linguistischer Annotationsverfahren wie Lemmatisierung, Wortartenzuordnung (Part-of-Speech tagging) oder Named Entitiy Recognition. Anschließend werden die Ergebnisse vom ACDH-CH in der Korpussuchmaschine NoSketch Engine online verfügbar gemacht. Dieses Werkzeug erlaubt die Suche und Auswertung der signifikanten Textmengen im amc und macht das Korpus in Kombination mit den verfügbaren Annotationen erst für die effiziente Bearbeitung quantitativer und qualitativer Forschungsfragen tauglich.
In der folgenden Lernressource machen Sie sich mit grundlegenden Begrifflichkeiten vertraut und erlernen das Formulieren von Suchanfragen in der Sketch Engine/NoSketch Engine. Insbesondere wird Ihnen die in dieser Korpussuchmaschine verwendete Abfragessprache Corpus Query Language (CQL) näher gebracht.
Grundlagen: Token vs. Strukturen
Bei der Suche mithilfe von SkE/NoSkE gibt es einige Grundbegriffe, mit denen Sie sich vertraut machen sollten. Prinzipiell wird in der Suchmaschine und ihrer Abfragesprache CQL zwischen Token und Strukturen unterschieden.
Token
Token sind das Ergebnis des sogenannten Tokenisierungsprozesses – d.h. der Zerlegung des Eingangstexts in linguistisch sinnvolle Einheiten. In der Regel entspricht ein Token einem orthographischen Wort. Die simpelste Tokenisierungsstrategie wäre: alles was zwischen zwei Leerzeichen steht, ist ein Token.
Diese vereinfachte Darstellung muss freilich um die Berücksichtigung von Satzzeichen ergänzt werden: Satzzeichen sollen vom vorangehenden Wort abgetrennt werden und bilden separate Token. Die Existenz von Abkürzungen verkompliziert die Tokenisierung etwas: zum Beispiel sind die Punkte in z.B. natürlich keine Satzzeichen, dürfen daher nicht abgetrennt werden, denn z.B. sollte als ein einziges Token behandelt werden.
Token-Attribute
Die Informationen, die jedem Token zugeordnet werden, werden in der SkE (Token-)Attribute genannt.
Einige der Token-Attribute im amc wären
word: das einfachste Attribut. Es beinhaltet, wie der Name andeutet, die orthographische Form des Wortes.lemma: hier steht die Grundform des Wortes (wie es von einem Lemmatisierungsprogramm ermitteln wurde).lc: eine lower cased Version des Wortes. Die Suche in CQL ist case sensitive,lckann verwendet werden, um case insensitive zu suchen, also Unterschiede in der Großkleinschreibung zu ignorieren. D.h. eine Suche[word="Ciao"]findet nur genau “Ciao”. Die Suche[lc="ciao"]findet ciao, Ciao, CIAO, CiAo, etc.posTT: part-of-Speech tags nach dem STTS-Tagset, wie sie vom PoS tagger TreeTagger vergeben wurden.pos: part-of-Speech tags, wie sie vom PoS tagger RFTagger vergeben wurden: zusätzlich zur Wortart werden auch morphologische Informationen angegeben.
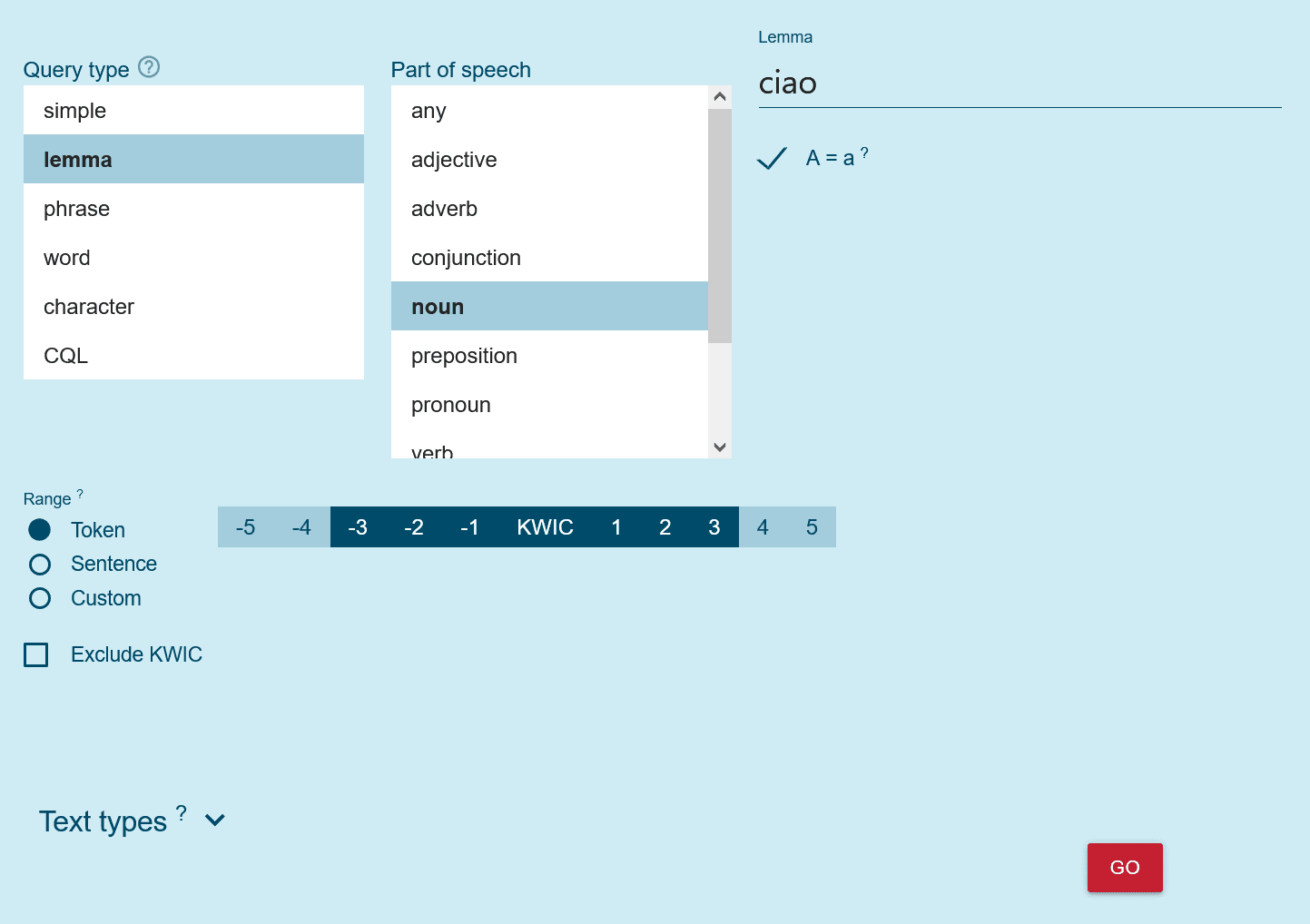
Einfache Token-Suche nach ‘ciao’ als Lemma.
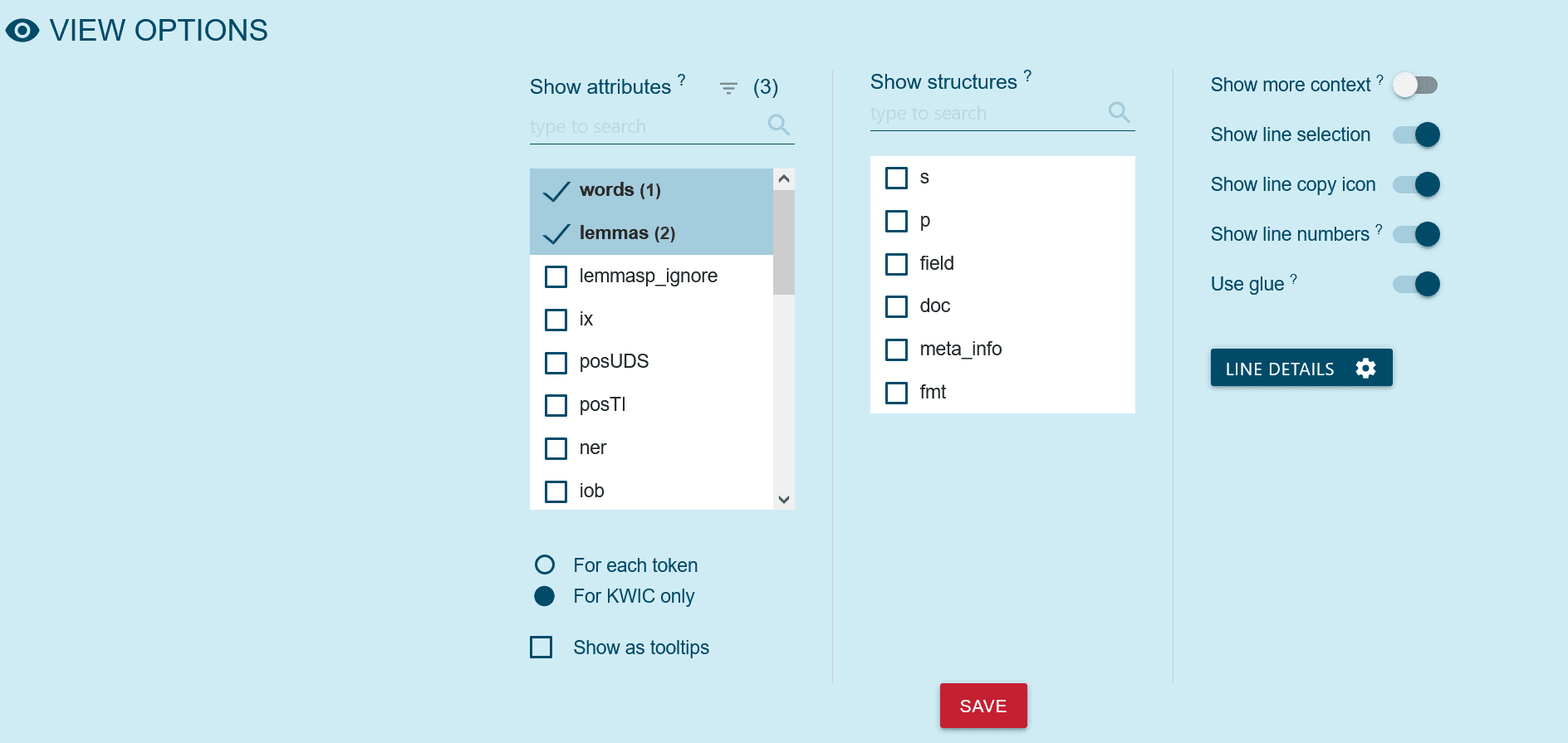
In den View Options kann man die Attribute, die den Token im Korpus zugeordnet sind, auswählen.

Beispiel-Suchergebnis für das Token ‘ciao’. Es wurden die Attribute word, lemma, posTT, und pos ausgewählt. Die Information ist unter dem Token sichtbar.
Strukturen
Die Token eines Textes sind typischerweise in hierarchische Strukturen eingebettet. Zum besseren Verständnis dieses Konzepts hier ein Beispiel dafür, wie für den Import in die SkE aufbereitete Textdaten konkret aussehen.
<doc id="APA_20170101_APA0001" datum_full="2017-01-01T00:11:16Z"
datum="2017-01-01" bibl="APA-Meldungen digital vom 2017-01-01"
docsrc_name="APA-Meldungen digital"
region="agesamt"
mediatype="print"
Tokens="180"
ressort2="chronik ausland unzuordenbar"
autor="fre"
>
<p>
<s>
Maschine N.Reg.Nom.Sg.Fem NN Maschine-n
mit APPR.Dat APPR mit-i
mehr PRO.Indef.Attr.-.*.*.* ADV mehr-r
als CONJ.Comp.- KOKOM als-c
hundert CARD CARD hundert-m
Menschen N.Reg.Dat.Pl.Masc NN Mensch-n
an APPR.An APPR an-i
Bord N.Reg.Dat.Sg.Neut NN Bord-n
sollte VFIN.Mod.3.Sg.Past.Subj VMFIN sollen-v
nach APPR.Dat APPR nach-i
Mexiko N.Name.Dat.Sg.Neut NE Mexiko-n
fliegen VINF.Full.- VVFIN fliegen-v
...
</s>
</p>
...
</doc>
Dieses Datenformat nennt sich (in der SkE-Terminologie) “Vertikale”.
Wie Sie sehen können, ist der Text tokenisiert. Jedes Token steht in einer separaten Zeile und diese Zeilen enthalten, in Spalten organisiert, die Wortform (also formal gesprochen das Token-Attribute word) gefolgt von den anderen Token-Attributen - in diesem Fall pos, posTT und lempos (eine Kombination aus Lemma und PoS).
Und diese tokenisierten Texte können nun durch Struktur-Elemente, nun ja, strukturiert werden. Im Beispiel ist zu erkennen, wie diese Struktur-Elemente als XML-artige Spitzklammer-Annotationen die Token ergänzen.
Typische Strukturen sind Dokumente, Paragraphen (Absätze) und Sätze, die im amc als <doc> <p> und <s> ausgezeichnet werden. Die Strukturen können Zusatzinformationen in Form von Struktur-Attributen enthalten.
Typischerweise finden sich in den Attributen des <doc>-Elements die Metadaten zum entsprechenden Dokument. Im amc entspricht der Inhalt eines <doc>-Elements einem Zeitungsartikel. An Metadaten sehen wir im Beispiel Attribute wie id, datum, autor, docsrc, ressort2, etc.
Quiz
Schnelleinstieg: Suche mit “Simple search”
Die einfachste Form der Suche im amc ist die sogenannte Simple search.
Diese kann in der SkE innerhalb der “Concordance”-Funktion aufgerufen werden:
- entweder durch Auswahl des Concordanece-Symbols im linken Menü und dann weiter unter dem Reiter “basic”
- oder im Dashboard über den Auswahlpunkt “Concordance”. Die Funktionalität der simple search wird dann auch hier wieder unter dem Reiter “basic” angezeigt.
Gibt man hier eine Wortform ein, so sucht die SkE
- dieses Wort — und zwar case-insensitiv, d.h. ohne Berücksichtigung von Groß- und Kleinschreibung. Die Eingabe von SMS findet daher z.B. SMS, sms, Sms, etc.
- entspricht die Sucheingabe auch einem Lemma, dann auch alle Flexionsformen dieses Lemmas. (D.h. eine Suche nach Haus findet daher auch alle Flexionsformen des lemmas Haus: das wären Haus, Hauses, Hause, Häuser, Häusern.)
Mehrwort-Suche
Es kann auch eine Abfolge mehrerer Wörter angegeben werden, die SkE sucht dann nach genau dieser Abfolge, z.B. ein schönes Haus.
Da bei der Simple search wie erwähnt auch nach den Wortformen eines Lemmas gesucht wird, findet eine Suchanfrage schön Haus auch alle Paarungen der Wortformen des Lemmas schön und der Wortformen des Lemmas Haus und das unabhängig von Groß- oder Kleinschreibung. Somit erscheinen im Ergebnis z.B. schönes Haus, schönsten Hauses, Schöneren Häusern etc.
Wildcards
In der Simple search ist die Verwendung des Wildcards * (Jokerzeichen, Asterisk) möglich: es steht für beliebig viele (auch null!) beliebige Zeichen.
Beispiele:
- Haus
*: alle Wörter, die mit der Buchstabenfolge Haus beginnen: Haus, Hauses, Hausmaus, Haussa, Hausbesorgerin … aber auch alle Wortformen von Lemmata, die mit Haus beginnen. Es wird also z.B. auch Häusern gefunden. *aus : alle Wörter, die mit der Buchstabenfolge aus enden: aus, Maus, Haus, Schildlaus, …- Ha
*s: alle Wörter, die mit Ha beginnen, und mit s enden: Has, Haus, Hass, Handelsabschluss, Hafenmeistergattinnenpendlerbus, etc. Wegen der beiden speziellen Eigenschaften case-insensitiv und Lemma-Suche wird aber auch z.B. haltlos (case-insensitive) und haltlose gefunden (Ergebnis der impliziten Lemma-Suche, obwohl die gefundene Wortform dann gar nicht auf s endet!)
Ein weiteres Beispiel für den case-insensitiven Charakter der Simple search: deutsch* findet: deutsch, deutsche, deutsches … aber auch: Deutschlands, Deutschmatura,…
”Vollsuche” mit der Corpus Query Language (CQL)
Wie wir gesehen haben, kann in der Simple search nur nach Token und dabei auch nur nach Wortformen und (implizit) Lemmata gesucht werden, oder exakter ausgedrückt: es kann nach Werten im Attribut word gesucht werden (wobei implizit intern zusätzlich auch noch die Attribute lc und lemma zur Suche mitherangezogen werden).
Im Gegensatz hierzu bietet die CQL weit mehr Möglichkeiten:
- Suche in beliebigen (Token-)Attributen
- Suche unter Berücksichtigung von Strukturen und deren Attributen
- Suche mit regulären Ausdrücken
- uvm.
Suche auf der TOKENEBENE in CQL
Suchanfragen mit der CQL werden wieder unter Concordance, diesmal im Reiter Advanced unter Auswahl des Query type CQL eingegeben. In der Suche mit CQL wird jedes Token durch eckige Klammern bezeichnet. Innerhalb dieser Klammern werden dann die Bedingungen angegeben, welche die Attribute dieses Token erfüllen müssen:
[ word="Haus" ]Alle Einträge, bei denen das Attribut “word” den Wert “Haus” aufweist — also alle Token mit exakt der Buchstabenfolge “Haus”[ lemma="Haus" ]Alle Einträge, bei denen das Attribut “lemma” den Wert “Haus” aufweist — also “Haus” “Hauses” … “Häusern”[ posTT="NN" ]Alle Einträge, bei denen das Attribut “posTT” (dieses bezeichnet die PoS-Annotationen durch den TreeTagger) den Wert “NN” aufweist — also alle Nomen[](leere Klammern, also KEINE Bedingungen). Da hier für das Token keine weiteren Einschränkungen angegeben wurden, findet diese Suche ausnahmlos ALLE Token!
Für die Suche nach Mehrwortausdrücken können die gewünschten Bedingungen für die Einzelworte einfach aneinandergereiht werden:
[ posTT="ADJA" ][ lemma="Haus" ]: alle Token mit der Wortart (attributives) Adjektiv, gefolgt von einem Eintrag mit dem Lemma “Haus” also z.B. schönes Haus, hohe Häuser, niedrigen Häusern, …

Beispielhaftes Abfrageergebnis zur CQL-Abfrage attributives Adjektiv + Haus. Links oben sehen Sie die Suchabfrage und die Anzahl der gefundenen Ergebnisse. Mittig finden Sie die ersten Suchergebnisse. Sie sehen in rot die gefundenen Formen im Text, in grau darunter das jeweilige Lemma.
Reguläre Ausdrücke
In der CQL können sogenannte reguläre Ausdrücke (regular expressions, Regex) verwendet werden, womit die Ausdrucksmächtigkeit und Flexibilität der Suche ernorm erhöht wird. Die wichtigsten “Bausteine” bei der Zusammenstellung eines regulären Ausdrucks sind:
- “
.” : Ein Punkt steht als Platzhalter für jedes beliebige Zeichen, z.B.[word="Ha.s"]findet “Haus” “Hass” “Hals” … - ”
*” : steht für 0, 1 oder beliebig viele Wiederholungen des vorhergehenden Zeichens oder Ausdrucks. z.B.[word="Hallo*"]findet “Hall” “Hallo” “Halloo” etc. - ”
+” : steht für 1 oder beliebig viele Wiederholungen des vorhergehenden Zeichens oder Ausdrucks, z.B.[word="Hallo+"]findet “Hallo” “Halloo” etc. … aber nicht “Hall”. D.h., das Zeichen vor*ist optional, das Zeichen vor+hingegen ist obligat! - ”
?” : steht für 0 oder genau 1 Wiederholung des vorhergehenden Zeichens oder Ausdrucks, z.B.[word="Hallo?"]findet genau die beiden Formen “Hall” und “Hallo”. D.h. das?steht für die Optionalität aber nicht für die Wiederholbarkeit des linken Nachbarn von?.
Kombination mit .: Üblich ist es, *, +, ? mit . (dem Platzhalter für jedes beliebige Zeichen) zu kombinieren.
[word=".?und"]findet und, Mund, Hund, wund, rund, …[word="Hunde.+"]findet Hundehütte, Hundekuchen, Hundefriseur, aber natürlich auch Hunderttausend … (aber nicht Hunde!)[pos="N.Reg.*Pl.*"]findet alle Nomen im Plural
Quiz
Wiederholungen
Alternativ zu *, +, ? kann man mit dem ranges Operator nicht nur festlegen, ob ein Ausdruck 0, 1, oder “öfter” wiederholt werden soll, sondern es kann die exakte Mindest- und Maximalzahl an Wiederholungen spezifiziert werden.
Die allgemeine Syntax für diesen Operator lautet: {minimale Anzahl, maximale Anzahl}
Damit gilt: x{0,1} bedeutet minimal 0 und maximal 1 Wiederholungen von x (und entspricht damit x?). x{1,} bedeutet minimal 1 und eine uneingeschränkte maximale Anzahl an Wiederholungen von x (und entspricht damit x+). x{0,} bedeutet minimal 0 und eine uneingeschränkte maximale Anzahl an Wiederholungen von x (und entspricht damit x*).
Beispiele:
[word=".{10}"]genau 10 Wiederholungen von ”.” – also alle Wörter oder Zahlen mit einer Länge von 10 Zeichen[word=".{10,}"]mindestens 10 Wiederholungen von ”.” , keine Angabe der Maximalzahl: also alle Wörter oder Zahlen mit einer Mindestlänge von 10 Zeichen[word=".{10,15}"]Wörter mit mindestens 10 und maximal 15 Zeichen[posTT="ADJ."]{2,}Abfolge von mindestens 2 Adjektiven ( “ADJ.” findet sowohl ADJA als auch ADJD, d.h. attributive und prädikative/adverbiale Adjektive)[posTT="ADJ."] []{0,2} [lemma="Haus"]Abfolge von einem ADJ und dem Lemma “Haus”, wobei zwischen Adjektiv und dem Nomen Haus bis zu 2 beliebige zusätzliche Token stehen können.
Logische Verknüpfungen
Es stehen die logischen Operatoren & (logisches UND) und | (logisches ODER) zur Verfügung.
A | B logisches oder : es muss zumindest eine der beiden Bedingungen A oder B erfüllt sein.
[word="Das|das"]suche alle “Das” oder “das”[pos="ADJA|ADJD|ADV"]suche alle Adjektive oder Adverben
A & B logisches und: es muss sowohl Bedingung A als auch Bedingung B erfüllt sein.
[word="schön" & posTT="ADV" & pos="ADV.*"]finde “schön”, wenn sowohl der TreeTagger (posTT) als auch der RFTagger (pos) es als Adverb markiert haben.
Gruppierung mit ( )
In regulären Ausdrücken können einzelne Komponenten mit ( ) zu Unterausdrücken zusammengefasst werden, die dann wiederum mit den schon bekannten Operatoren * ? + | & und {min,max} kombiniert werden können.
[word="(Das|das)"]finde alle Das oder das Token[word="(D|d)as"]finde alle Das oder das Token[lc="(ur|vor){2,}"]findet alle Wortformen (unabhängig von der Groß-Kleinschreibung) die mit zumindest 2 “ur” oder “vor” beginnen, z.B. vorvorgestern oder Ururgroßvater (aber auch Vorurteil!)[lc="(ha|he|hi|ho|hu){3,}"]findet alle Wortformen (unabhängig von der Groß-Kleinschreibung) die aus mindestens 3 Wiederholungen von ha, he, hi … bestehen - also hahaha, hihihihihi, etc.
Gruppierungen können auch innerhalb anderer Gruppen platziert werden:
([lemma="groß.*"] ([lemma="Haus"]|[lemma="Gebäude"])) | ([lemma="klein.*"] [lemma="(Hütte|Kate|Behausung)"])sucht nach großen Häusern und Gebäuden oder kleinen Hütten und Behausungen (aber findet auch “großindustrielle Häuser” und die “Kleinarler Hütte”)[lc="(h(a|e|i|o|u)){3,}"]Eine alternative Formulierung um alle Wortformen zu finden, die aus mindestens 3 Wiederholungen von ha, he, hi … bestehen
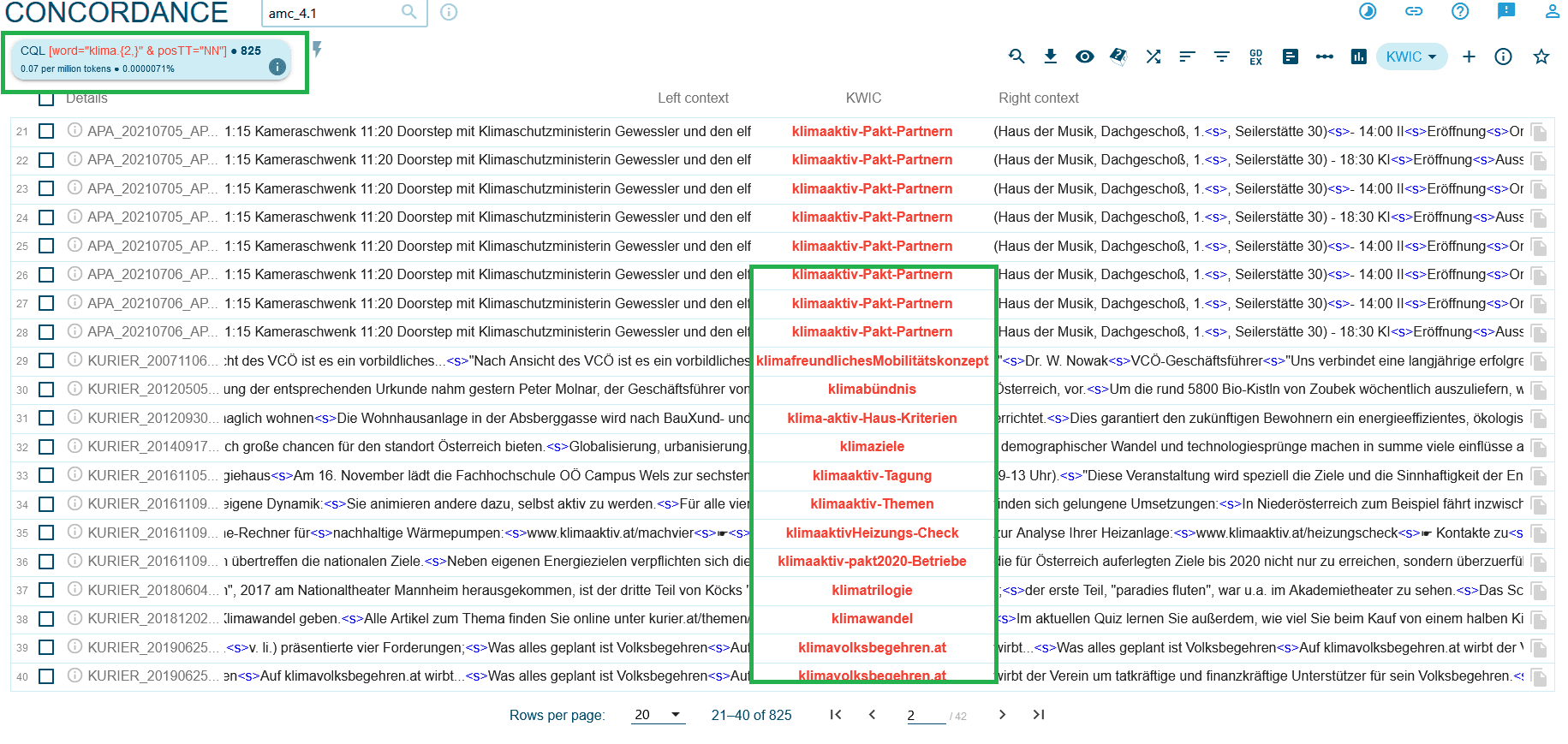
Screenshot der Suche im AMC_4.1 des Ausdrucks “klima” mit mindestens zwei Wiederholungen, die als Nomen im Treetagger getaggt wurden. Oben links sehen Sie den Suchausdruck, in der Mitte das Ergebnis. Alle gefundenen Begriffe sind als Nomen getaggt. Auch der Tippfehler “klimafreundlichesMobilitätskonzept”, zusammengesetzte Nomen mit Bindestrich oder auch der Name einer Webseite mit Punkt werden gefunden.
Zeichenklassen mit [ ]
Wir haben bisher den Platzhalter . verwendet, der für jedes beliebige Zeichen steht. Mit dem Operator [ ] steht eine Möglichkeit bereit, eine Auswahl an Zeichen, also eine Zeichenklasse zu definieren:
[abc]steht für einen der Buchstabenaoderboderc- ist also äquivalent zu(a|b|c)[word="H[oa]se"]findet daher Hose und Hase - und ist also äquivalent zu[word="H(o|a)se"][lc="[ptkbdg].+"]findet alle Wortformen, die mit einem Plosiv beginnen - und ist also äquivalent zu[lc="(p|t|k|b|d|g).+"][lc="(h[aeiou]){3,}"]Eine weitere alternative Formulierungsmöglichkeit um alle Wortformen zu finden, die aus mindestens 3 Wiederholungen von ha, he, hi … bestehen
Die bisherigen Beispiele lassen sich wie gezeigt auch mit der Verwendung von Gruppierung ( ) zusammen mit | formulieren. Die Zeichenklassendefinitionen bieten aber noch Möglichkeiten, die darüber hinausgehen:
Bereiche mit - definieren:
[a-z]und[0-9]stehen für den Buchstabenbereich von a bis z bzw. den Zahlenbereich von 0 bis 9[word="[0-9]+"]findet alle Zahlen[word="[0-9]+([,.][0-9]+)+"]findet alle Zahlen - die auch.oder,enthalten können. Also z.B. 0815 aber auch 19.500.123,00<doc year="199[0-5]"/>findet alle Artikel von 1990-1995.
Negation mit [^ ...] definieren:
[^abc]ein ”^” unmittelbar am Anfang der Zeichenklassendefinition bedeutet, dass die Zeichenklasse aus allen Zeichen außer den danach angeführten besteht!- [lc =
"[^ptkbdg].+"] verwendet z.B. eine Zeichenklasse “nicht p,t,k,b,d,g” ,und findet daher alle Wortformen, die nicht mit einem Plosiv beginnen.
Quiz
Regex auch auf Token-Ebene
Die Operatoren für reguläre Ausdrücke können nicht nur auf den Inhalt von Token-Attributen — also auf der Buchstabenebene — angewendet werden, sondern auch auf ganze Token oder Abfolgen von Token:
[word="ein"] [pos="ADJ.*"]* [word="Haus"]findet “ein” und “Haus” mit beliebig vielen optionalen Adjektiven dazwischen: ein Haus, ein schönes Haus, ein schönes großes Haus, …[lemma="schön"] []{0,4} [word="Haus"]findet “schön” gefolgt von Haus – in einem Abstand von maximal 4 Token. (Zur Erinnerung: das leere[]passt auf jedes beliebige Token.)([lemma="schön"]|[lemma="groß"]) [lemma="Haus"]findet “schön” oder “groß” + “Haus”. (und ist äquivalent zur Anfrage[lemma="schön|groß"] [lemma="Haus"])
Gleichzeitiges Suchen im linken und rechten Kontext: meet und union
Bisher konnten wir nur entweder im linken oder im rechten Kontext suchen. Mit meet kann in beiden Kontexten gleichzeitig gesucht werden:
(meet [TokenA] [TokenB] -linker_context rechter_context)
sucht nach [TokenA] in deren linker oder rechter Nachbarschaft ein [TokenB] zu finden ist. Was als “Nachbarschaft” gilt, wird dabei über die Zahlen in -linker_context und rechter_context bestimmt.
z.B.: Suche nach dem Lemma “Hund” in dessen linker oder rechter Umgebung im maximalen Abstand von 5 Token die Lemmas “beißen” oder “bissig” stehen.
(meet [lemma="Hund"] [lemma="(beißen|bissig)"] -5 5)
Quiz

AMC 4.1. Suche in der Konkordanz, schützen und Klima im Kontext. In grün und gelb das Wort Klima in verschiedener Bedeutung.
Suche auf Strukturebene in CQL
Sowohl bei der Simple search als auch bei den bisherigen Beispielen zur CQL blieben Informationen auf der Strukturebene (Dokumente, Absätze, Sätze) unberücksichtigt. Hier wird nun gezeigt, wie auf und mit Strukturinformationen gesucht werden kann. Wie oben gezeigt, werden Struktur-Informationen in den Input-Daten für die SkE mithilfe von XML-Elementen kodiert. In HTML und XML gelten die folgenden Notationskonventionen:
<S>Beginn-tag einer Struktur namens “S”</S>End-tag einer Struktur namens “S”<S/>Die gesamte Stuktur “S” von Beginn bis Ende.
Mit dieser Kodierungskonvention arbeiten wir auch in der Suchabfragesprache CQL.
In amc steht die Struktur “doc” (Dokument) für einen Zeitungsartikel, d.h.
<doc />Findet alle (Zeitungs)Artikel<doc>Findet alle Artikelanfangsmarker<doc> []Findet das erste Token jedes Artikels[] </doc>Findet das letzte Token jedes Artikels
Strukturen können bekanntlich ihre eigenen Attribute aufweisen, und nach diesen kann wie folgt gesucht werden:
<doc id="xyz"/>Artikel mit der id “xyz”<doc docsrc="STANDARD" & year="2017"/>Artikel aus der Zeitung “Der Standard” aus dem Jahr 2017 (beachten Sie, dass ein logisches & verwendet werden muss: Sie suchen nach Artikeln die zwei Bedingungen erfüllen müssen: sie müssen aus dem “STANDARD” stammen UND das Veröffentlichungsjahr 2017 haben)
Für die Spezifikation der Werte der Strukturattribute können reguläre Ausdrücke genauso verwendet werden, wie es oben bereits für den Inhalt von Token-Attributen demonstriert wurde:
<doc year="199."/>: alle Artikel aus den 1990ern<doc year="1998|1989)"/>oder<doc year="199(8|9)"/>oder<doc year="199[89]"/>: alle Artikel aus 1998 oder 1999
within/ containing
Mit containing und within können Bedingungen auf Strukturen und auf Token miteinander kombiniert werden:
containing: wird verwendet um Einschränkungen auf Strukturen auszudrücken: es wird nach Strukturen gesucht, die bestimmte “Dinge” enthalten. z.B. alle Sätze, die das Wort “Haus” beinhalten:
<s/> containing [word="Haus"]
within: wird verwendet um Einschränkungen auf Token auszudrücken: es wird nach Token gesucht, die sich in bestimmten Strukturen befinden. z.B. alle Fundstellen für “Haus”, aber nur, wenn sie in einem Artikel des “STANDARD” stehen, der 2010 oder später erschienen ist.
[word="Haus"] within <doc docsrc="STANDARD" & year>="2010"/>- Auch die Verwendung von Negation (
not) ist im Zusammenhang vonwithinundcontainingmöglich: z.B. suche nach “Ball” — aber nicht im Sportressort (das wäre ein Versuch, eher Beispiele mit der Bedeutung Tanzball zu finden) [word="Ball"] not within <doc ressort2="sport"/>
Merken Sie sich am besten einfach, dass containing und within sich exakt so verhalten, wie Sie es von ihrer Wortbedeutung in Englischen erwarten würden!
<s/> containing [word="Haus"]: search for any structure<s>which iscontaininga token[word="Haus"][word="Haus"] within <doc docsrc="STANDARD"/>search for any token[word="Haus"]which is locatedwithina structure<doc docsrc="STANDARD"/>
containing und within können auch miteinander kombiniert werden und es gibt sehr sinnvolle Anwendungen dafür! Typischerweise wird das eingesetzt um Kontexte zu filtern. Beispielsweise könnte man auf der Suche nach Nennungen des Wortes Ball in der Bedeutung Tanzball auf Artikel einschränken,
in denen typische Tanzballbegriffe vorkommen:
[lemma="Ball"] within ( <doc ressort2 != "sport"/> containing [lemma="(Walzer|Polonaise|Champagner|Mitternachtseinlage)"] )
Also: suche nach “Ball” innerhalb von Artikeln, die nicht aus dem Sportressort stammen, und in denen auch Walzer, Polonaise, Champagner oder Mitternachtseinlage vorkommen. Damit schränkt sich die Trefferanzahl für “Ball” im amc von ca. 800.000 auf “nur noch” ca. 50.000 ein. (Aber freilich gibt es darunter immer noch Artikel über Fußball, die nicht korrekt mit Sportressort markiert wurden und in denen Siege mit Champagner gefeiert werden, oder Spieler mit dem Eigennamen “Walzer” vorkommen)
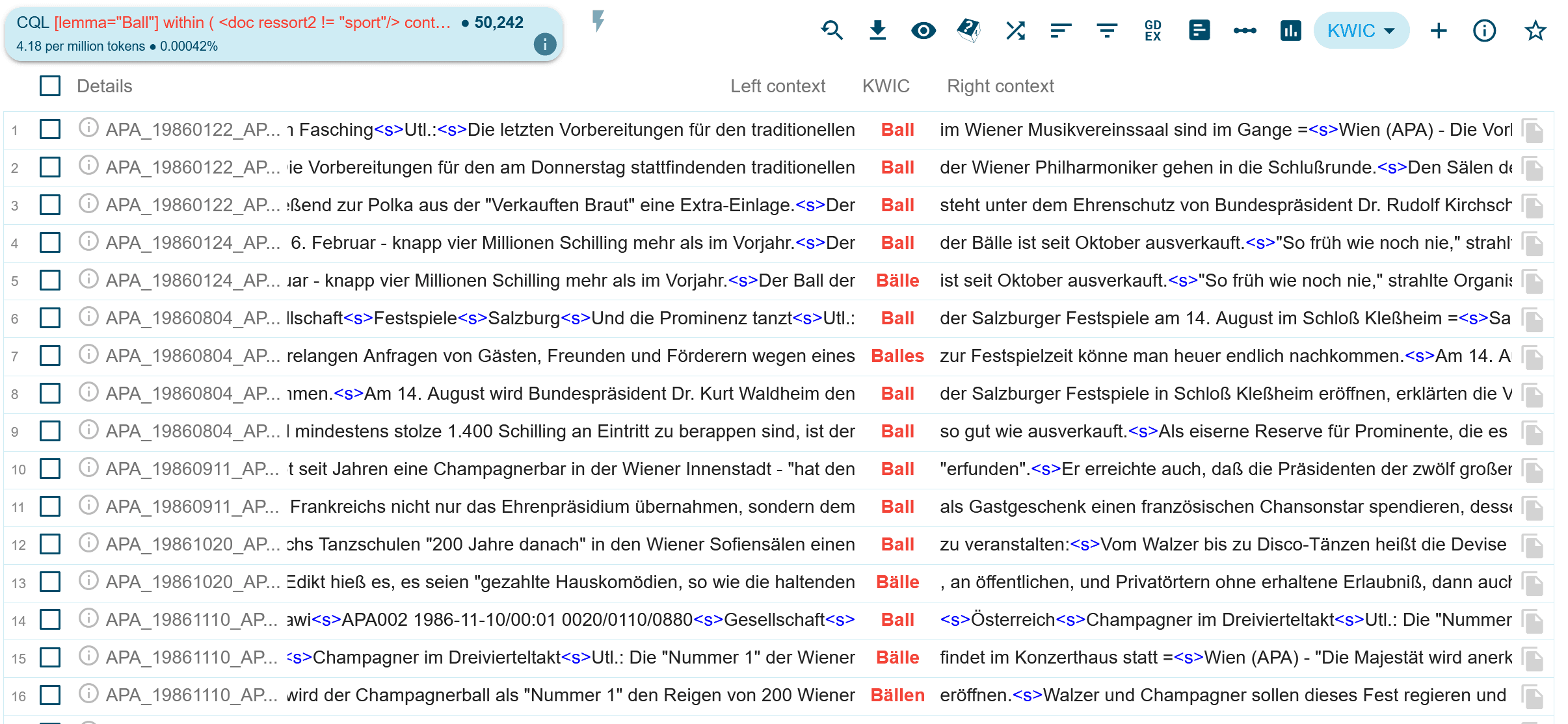
Die oben genannte Suche liefert im AMC 4.2. Ergebnisse, die sich auf “Bälle” im Sinne von “Tanzveranstaltungen” beziehen. Die mit containing gesuchten Lemma müssen nicht in direkter Nachbarschaft des Suchbegriffs “Ball” vorkommen, sehr wohl aber in den Artikeln, aus denen die Suchergebnisse stammen.
Tipps & Tricks
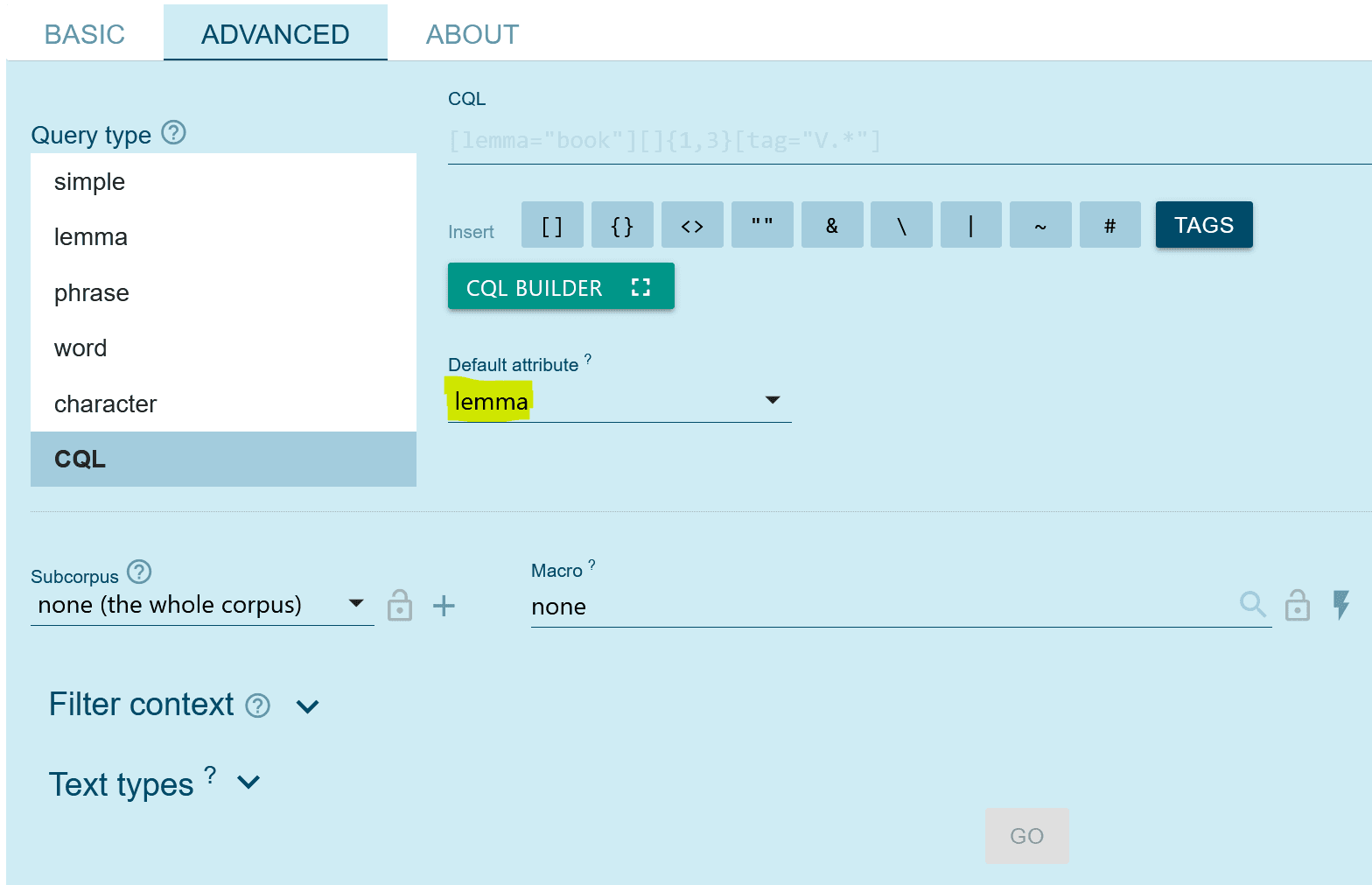
In der Advanced-Suchmaske sehen Sie in gelb unter der Schaltfläche für den CQL-Builder das Default attribute markiert. Beide Funktionen erleichtern die Erstellung von Abfragen.
Vereinfachte Schreibweise
In der ADVANCED Suchmaske befindet sich unter dem Feld CQL ein Auswahlfeld für ein Default attribute, das mit dem Wert lemma vorausgefüllt ist. Bei Abfragen auf dieses Attribut ist lemma quasi der Default des Default. Es gilt also:
- statt
[ lemma="Paradeiser" ]kann (bei einem default attribute “lemma”) vereinfacht"Paradeiser"geschrieben werden (die doppelten Anführungszeichen bleiben aber weiterhin verpflichtend!)
CQL Builder
Direkt unter dem Eingabefeld für CQL findet sich auch ein Schaltknopf namens CQL BUILDER – ein Tool, das bei der Formulierung von CQL-Anfragen helfen kann. Es kann durchaus sinnvoll sein, mit diesem Tool mit dem bisher erworbenen Wissen zu experimentieren, auch um weitere Funktionen zu entdecken. Genauere Erläuterungen finden sich in der Beschreibung des CQL Builders auf dem Sketch Engine Portal.
Escaping von Sonderzeichen
Da die Zeichen . + * & | ( ) [ ] in den CQL Abfragen eine Sonderbedeutung als Bestandteile regulärer Ausdrücke haben, müssen sie speziell gekennzeichnet werden, wenn man buchstäblich nach ihnen suchen will. Dieses Aufheben der Sonderbedeutung nennt man escapen eines Zeichens, und
passiert durch Voranstellen eines \ (backslash).
Das heißt
[word="etc."]hier steht.für jedes beliebige Zeichen (Anmerkung: die Suche nach “etc.” wird genauso noch die Abkürzung “etc.” finden, denn regular expression-Punkt “matcht” auch mit dem dem “buchstäblichen” Punkt wie eben jedes andere beliebige Zeichen)[word="etc\."]hier steht.tatsächlich für einen Punkt(.)[word="..."]findet daher alle Token mit 3 Zeichen[word="\.\.\."]findet genau punktipunktipunkti (3 Punkte)
Tokensuche ignoriert Strukturgrenzen
Standardmäßig werden Strukturgrenzen in der Suchanfrage vollständig ignoriert! Wenn sie nicht explizit angegeben werden, bleiben Strukturen für die CQL also quasi unsichtbar.
Das heißt
[] []findet alle benachbarten Token, selbst wenn dazwischen eine Strukturgrenze liegt.[posTT="ADJ.*"] [posTT="NN]wird also alle Adjekiv-Nomen-Kombinationen finden, auch über Satz-, Absatz- und sogar über Artikelgrenzen hinweg!
Abhilfe schafft hier nur die Verwendung von within:
[posTT="ADJ.*"] [posTT="NN] within <s/>beschränkt die Suche auf Fundstellen, die sich innerhalb ein- und desselben<s/>, also innerhalb eines Satzes, befinden, was in den meisten Fällen wohl das erwünschte und sinnvolle Suchverhalten sein wird.
Attribute mit MULTIVALUE
In der SkE können Attribute als MULTIVALUE definiert werden. Das bedeutet, solche Attribute enthalten potenziell mehrere unterschiedliche Werte, die durch ein Trennzeichen (MULTISEP) voneinander abgegrenzt werden. Das ist im amc bei vielen Attributen des <doc>-Elements der Fall. So könnte z.B. kann das Attribut mutation eine Wert "Länder,Abend,Morgen" aufweisen: es ist also als MULTIVALUE-Attribut definiert, das Kommas (,) als Trennzeichen verwendet.
Für die Suche hat das die Konsequenz, dass der Inhalt des Attributs automatisch in seine Einzelwerte aufgegliedert wird und einfach nach den Einzelwerten gesucht werden kann, es bleibt aber auch der unveränderte Originalinhalt durchsuchbar. Um beim Beispiel zu bleiben: ein <doc mutation="Wien,Abend,Morgen" .../> würde mit jeder der folgenden Suchanfragen gefunden
werden:
mutation="Wien"mutation="Abend"mutation="Morgen"mutation="Wien,Abend,Morgen"mutation=".+Abend.+"
Übersicht über die vorhandenen Attribute
Um sich einen Überblick über den Namen und den Inhalt der vorhandenen Attribute zu machen ist die CORPUS INFO sehr hilfreich. Zu dieser gelangt man alternativ über die gleichnamige Schaltfläche im Dashboard oder — meist bequemer — über das Informations-Ikon neben dem Korpusnamen, der in der NoSkE am oberen Rand jeder einzelnen Seite eingeblendet wird. In der CORPUS INFO werden nicht nur statistische Daten über das Korpus angezeigt, sondern auch die Namen aller verfügbaren Token-Attribute, Strukturen und Struktur-Attribute.
Informationen zu den Strukuren finden sich dabei unter dem Titel TEXT TYPES. Informationen zu den jeweiligen Struktur-Attributen werden durch einfaches Klicken auf einen konkreten Strukturnamen ausgeklappt.
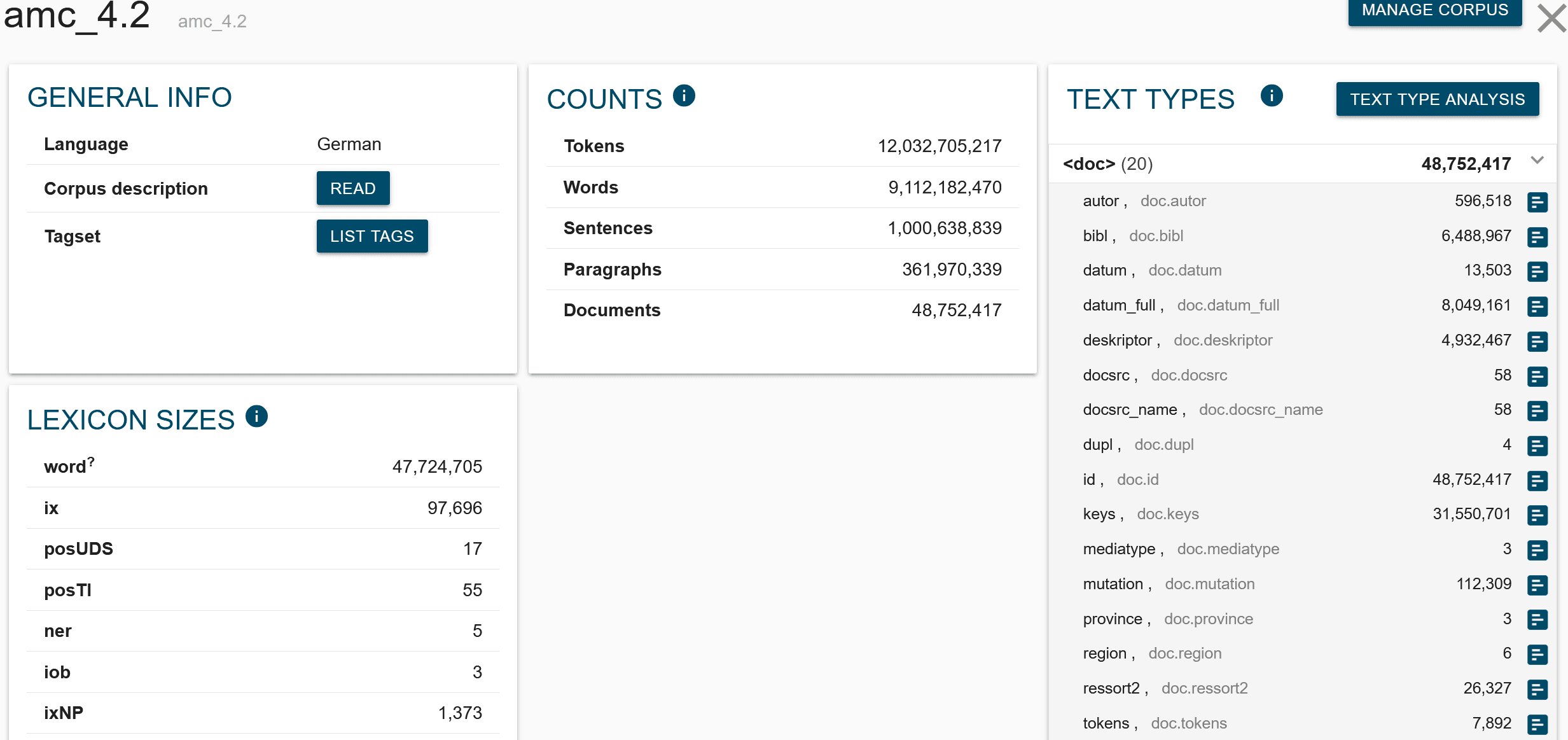
Die Corpus Info zeigt eine Übersicht aller vorhandenen Attribute, die bei der Suche in einem Corpus, in diesem Fall dem AMC 4.2, genutzt werden können.
Anzeige anpassen
Nach einer erfolgten Suche kann über Auswahl der View options (dem Auge-Symbol in der Werkzeugleiste) die Anzeige angepasst werden. Hilfreich ist, dass hier die Anzeige einzelner Attribute oder Strukturen ein- oder ausgeblendet werden kann. In View Options kann auch angegeben werden, ob die ausgewählten Attribute nur für den eigentlichen Treffer (meist die beste Wahl) oder für alle Wörter der KWIC-Liste angezeigt werden sollen. Weiters besteht die Option, die ausgewählten Attribute as tooltips, d.h. nur bei mouse over anzuzeigen.
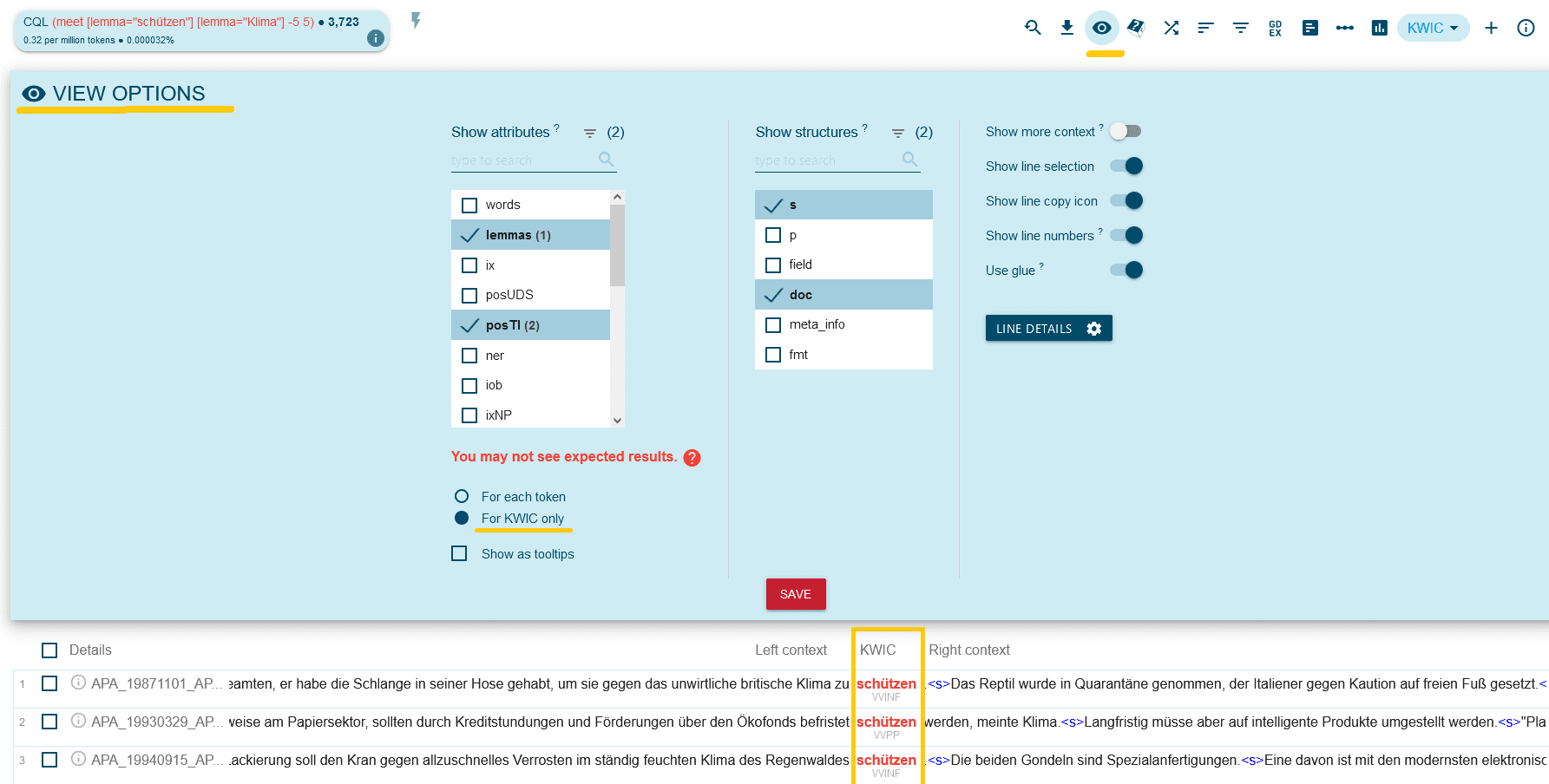
Für View Options muss das Auge-Symbol ausgewählt werden. Die Funktionsmaske “View options” zeigt hier die Auswahl “lemma” und “posTI”. Darunter sieht man die entsprechende KWIC-Ansicht eines Suchergebnisses.
Frequency
Suchergebnisse können mit der Option Frequency aus der Werkzeugleiste übersichtlicher zusammengefasst werden. Das ist oft hilfreich, um die Korrektheit einer Suchanfrage zu überprüfen. Bei der Analyse größerer Treffermengen kann es auch hilfreich sein, Frequenzlisten des linken oder
rechten Nachbarn des Suchworts erstellen zu lassen (Auswahl von 1L bzw. 1R). So lassen sich sehr oft “auffällige” Muster gut isolieren. Zum Beispiel liefert eine Suchanfrage nach der informellen Grußform “baba” ([lc="baba"]) ca. 10.000 Treffer. Erstellt man eine Frequenzliste der
linken Nachbarn von “baba”, so sticht an erster Stelle das Wort “Ali” mit ca. 1.800 Ergebnissen hervor, weil eben “Ali Baba” eine hochfrequente Wortfolge ist, die so einfach aus dem Gesamtzählergebnis exkludiert werden, oder bei der Verfeinerung der Suchanfrage berücksichtigt werden kann.
Einschränkungen der Metadaten ohne CQL Struktursuche
Wir haben gesehen, dass in der CQL oft Strukturelemente einbezogen werden, um die Suche nach bestimmten Kriterien in den Metadaten einzuschränken.
z.B. [word="Haus"] within <s docsrc="STANDARD|PRESSE" year>="2010"/> (“Haus” in STANDARD- oder PRESSE-Artikeln, die 2010 oder später erschienen sind.)
Alternativ können einfache Einschränkungen auf Basis der Metadaten auch im SkE user-interface vorgenommen werden. Dazu dient in der Suchmaske der Unterpunkt “Text Types”, wo die Suche auf <doc> mit spezifischen Attributwerten eingeschränkt werden kann.
Abgesehen davon, ist die dortige Auflistung der Attribute und ihrer möglichen Werte auch bei der Formulierung von CQL-Anfragen durchaus hilfreich, wenn man gerade nicht weiß, wie die Attributnamen genau lauten und welche Werte sie annehmen können.
Weiterführende Videos und Links
Allgemein zu SkE und Suche
- Concordance Introduction https://www.sketchengine.co.uk/user-guide/user-manual/concordance-introduction/
- Regular Expressions https://www.sketchengine.co.uk/user-guide/user-manual/concordance-introduction/regular-expression
- Corpus Querying https://www.sketchengine.co.uk/documentation/corpus-querying/
- CQL Basics https://www.sketchengine.co.uk/documentation/cql-basics/
- Link: Regular expressions Cheatsheet
Videos
Tagsets im amc
Kompakte Übersicht
- Das Stuttgart-Tübingen-PoS-Tagset (STTS) wie es im PoS-attribut posTT verwendet wird: https://www.ims.uni-stuttgart.de/forschung/ressourcen/lexika/germantagsets (dieser Link findet sich auch in der SkE selbst unter Corpus info -> Tagset Description)
- Tagset des RFTaggers wie es im PoS-attribut pos verwendet wird: https://www.sketchengine.eu/german-rftagger-part-of-speech-tagset
Detailierte Beschreibungen
De-facto wurden alle für das amc verwendeten PoS-Tagger auf dem TIGER Korpus trainiert. Ausführliche Dokumentationen der Annotations-Konventionen für das TIGER Korpus finden sich hier: http://www.ims.uni-stuttgart.de/forschung/ressourcen/korpora/TIGERCorpus/annotation
Insbesondere relevant für das amc sind: “A Brief Introduction to the TIGER Treebank”
”TIGER Morphologie-Annotationsschema”: Beschreibung der kombinierten PoS plus Morphoplogie-tags in pos: http://www.ims.uni-stuttgart.de/forschung/ressourcen/korpora/TIGERCorpus/annotation/tiger_scheme-morph.pdf