Grundlagen des Datenmanagements
- Written by
- Martina Trognitz
- Published on
- June 22, 2022
- Tagged with
- Data management
Lernziele
- Die Rolle und den Lebenszyklus von Daten in den Geisteswissenschaften verstehen
- Zentrale Fragen für die Datennutzung und Archivierung beantworten können
- Datenmanagement als wichtigen und zentralen Bestandteil der eigenen Forschung begreifen
- Grundlegende Regeln für Dateibenennung und Ordnerstrukturierung anwenden können
- Vor- und Nachteile von Dateiformaten für die Archivierung kennen
- Versionierungen effizient betreiben
A. Einleitung: Daten in der Gesellschaft und Geisteswissenschaftlichen Forschung
Daten begegnen uns in allen Bereichen des Lebens. Zumeist denkt man bei Daten an (Forschungs-)Gebiete wie Statistik, Biologie, Meteorologie, Finanzen oder Transportwesen. Doch Daten sind auch ein zentraler Bestandteil von geisteswissenschaftlichen Forschungen. Je nach Disziplin und Fragestellung arbeiten die Geisteswissenschaften mit unterschiedlichen Arten von Daten und Materialien, wie zum Beispiel:
- Primär- und Sekundärtexte,
- Audio und Videomaterial,
- Bilder und Objekte,
- 3D-Daten und Geoinformationsdaten oder auch
- Tabellen, Simulationen und Datenbanken. (Siehe Andorfer, “Forschungsdaten in den (digitalen) Geisteswissenschaften”; und DFG, “Umgang mit Forschungsdaten”.)
Je nach Forschungsgebiet wird in den Geisteswissenschaften nicht nur mit bestehenden Daten gearbeitet, sondern oftmals werden neue Daten produziert, zum Beispiel durch Umfragen, Audio- und Videoaufzeichnungen oder Digitalisierungen (siehe: DFG, “Umgang mit Forschungsdaten”). Im Sinne der guten wissenschaftlichen Praxis (siehe: ÖAWI, FWF, Research Integrity und DFG) sollten am Ende eines Projekts nicht nur die Ergebnisse, sondern auch die zugrunde liegenden Daten veröffentlicht werden. Dies erfordert, dass (Forschungs-)Daten nicht nur während des Projekts, sondern auch nach Ende des eigenen Forschungsprojekts langfristig zugänglich, wiederverwendbar, überprüfbar und reproduzierbar werden - unabhängig von ursprünglichen Datenersteller*innen oder Projektkontext. Zu diesem Zweck müssen die Daten während aller Projektphasen von der Planung bis zum Abschluss oder - anders ausgedrückt - während ihres gesamten Datenlebenszyklus verwaltet werden. Um eine möglichst reibungslose Arbeit mit den Daten während des Projekts und deren Nachnutzbarkeit zu gewährleisten, ist ein gutes Datenmanagement unerlässlich.
Einstiegsfragen:
Denken Sie an Ihre eigene Forschungsdisziplin und/oder Ihr Forschungsprojekt. Welche Antworten treffen auf Sie zu? Die Fragen dienen lediglich der Orientierung und es kann auch mehr als eine Antwort zutreffend sein.
B. Datenlebenszyklus & Datenmanagement
Daten sind das Herzstück eines jeden Forschungsprojekts, denn:
- Unser Wissen über ein bestimmtes Thema basiert auf Daten.
- Daten bilden den Ausganspunkt von Forschungsprojekten und -fragen.
- Das Arbeiten mit und Analysieren von Daten generiert neue Daten und neues Wissen im Verlauf eines Projekts.
- Neue Forschungsergebnisse beruhen auf Daten.
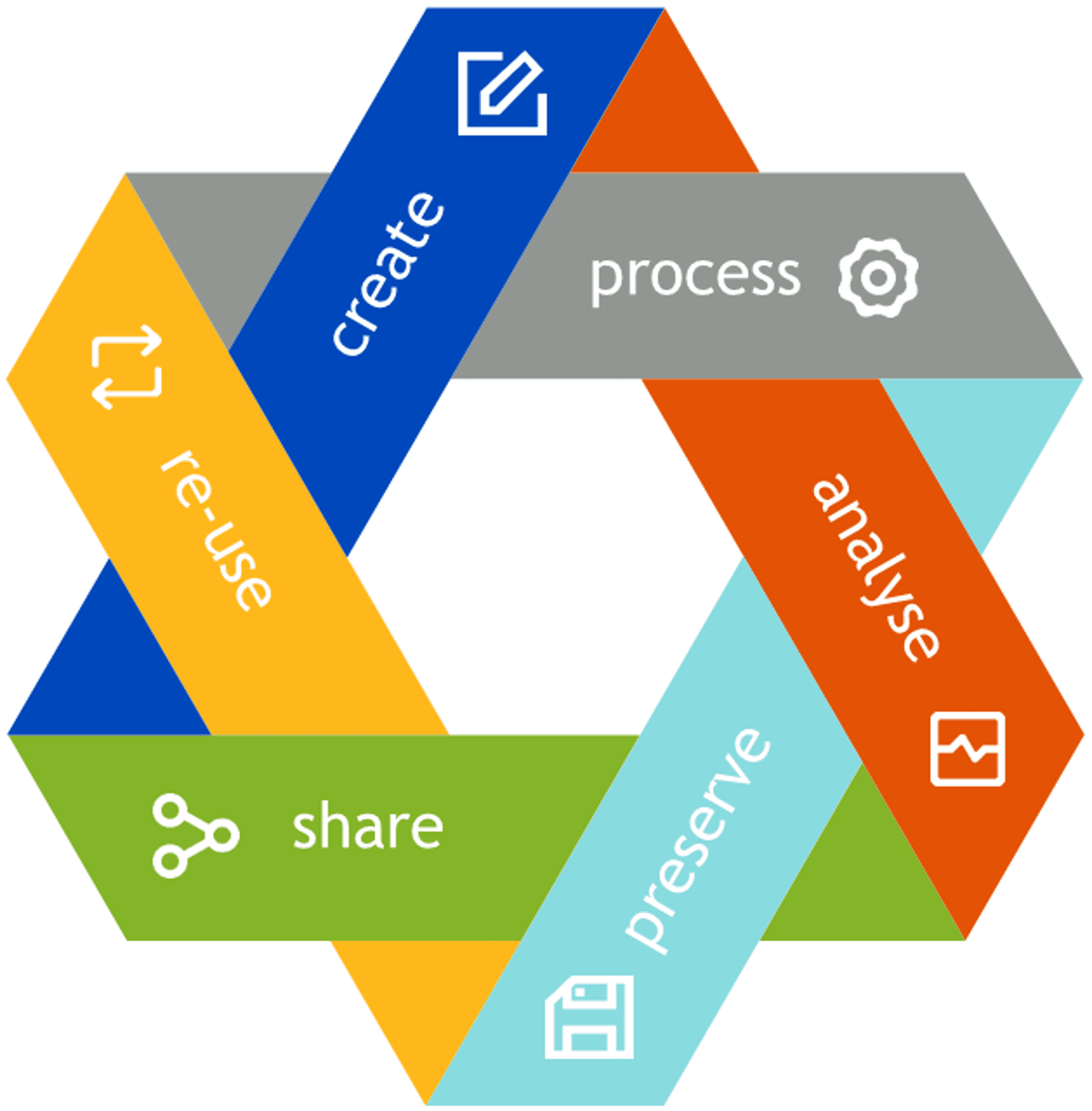
Abbildung: “DataLifeCycle”, von Martina Trognitz, lizenziert unter CC-BY 4.0. Die Abbildung basiert auf dem IANUS-Lebenszyklus und dem Zyklus des UK Data Service.
Üblicherweise haben (Forschungs-)Daten eine über ein konkretes Projekt hinausgehende Lebensdauer, was mit Hilfe des sogenannten Datenlebenszyklus (data life cycle) visualisiert wird: Im Laufe eines Forschungsprojekts werden Daten generiert (create), bearbeitet (process), analysiert (analyse), aufbewahrt (preserve), geteilt (share) und – im besten Fall – wiederverwendet (re-use). Die Grafik symbolisiert sehr gut, dass der Lebenszyklus von Daten aufrechterhalten werden sollte, damit die Bearbeitung darauf aufbauender Fragestellungen ermöglicht wird. Außerdem kann die Generierung von Daten oftmals kostenintensiv sein, weshalb eine langfristige Aufbewahrung der gewonnenen Daten besonders wichtig ist (siehe: IANUS, Lebenszyklus, und UK Data Service).
Welchen Gefahren Daten im Laufe ihres Datenlebenszyklus ausgesetzt sind, hat Franziska Mau in der Grafik “Lost Data Map” eindringlich visualisiert – kommt Ihnen die eine oder andere Gefahr bekannt vor?
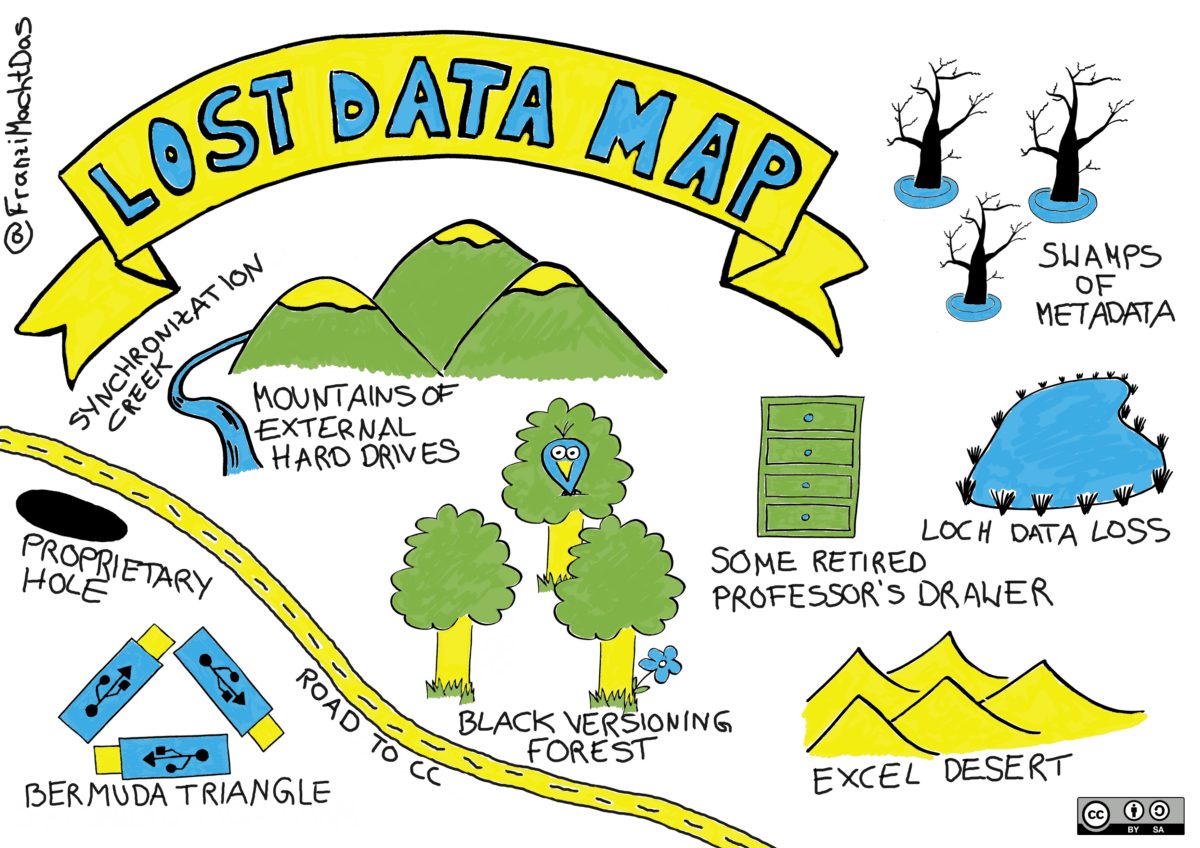
Abbildung: “Lost Data Map”, von Franziska Mau, FranziMachtDas.de, lizenziert unter CC BY-SA.
Eine oft genutzte aber besonders anfällige Methode für einen Datenverlust stellt die Speicherung von Daten auf USB-Sticks dar. Geht der Stick verloren oder ist dieser beschädigt, so sind auch die darauf gespeicherten Daten verloren. Dasselbe gilt für externe Festplatten. Außerdem stellt bei beiden Speichermedien die Synchronisierung mit lokalen Rechnern oder Netzlaufwerken eine Gefahrenquelle dar, da diese nicht immer einwandfrei klappt oder nicht regelmäßig durchgeführt wird und es somit zu Ungleichheiten im Datenbestand kommt. Eine weitere Gefahrenquelle für einen Datenverlust sind private Rechner oder externe Festplatten, die mit dem Ausscheiden einer Person aus einem Projekt nicht mehr zugänglich sind. Auch proprietäre Daten sind gefährdet, vor allem wenn die darauf abgestimmte Software nicht mehr zur Verfügung steht und die Daten daher nicht mehr auslesbar sind.
Im nächsten Abschnitt werden einige grundlegende und einfach anwendbare Prinzipien des Datenmanagements vorgestellt, um diese Tücken zu vermeiden.
Weiterführende Literatur und Links:
- Trognitz, Martina. “Der Lebenszyklus von Forschungsdaten.” IANUS, 7. August 2017.
- UK Data Service. “The importance of managing and sharing data.” University of Essex, 2012-2022.
C. Eine praktische Einführung in das Datenmanagement
C.1. Schritt 1: Die Planung - Gut vorbereitet in ein erfolgreiches Datenmanagement starten
Der erste wichtige Schritt für ein erfolgreiches Datenmanagement ist dessen Planung. Diese sollte am Beginn eines jeden Forschungsprojekts stehen, also bevor die Arbeit im Projekt startet bzw. an oder mit Daten gearbeitet wird. Die geplanten Abläufe des Datenmanagements in einem wissenschaftlichen Projekt werden in einem sogenannten Datenmanagementplan (DMP) dokumentiert. Ein Datenmanagementplan beantwortet unter anderem folgende Fragen:
-
Was möchte man mit dem Projekt erreichen?
-
Wie möchte man dieses Ziel erreichen?
-
Welche Vorgaben (zum Beispiel von den Fördergeber*innen) sind dabei zu erfüllen?
-
Welche Standards, Regulatoren und Verpflichtungen sind zu beachten und einzuhalten? Das beinhaltet:
- Nationale/internationale Gesetze, Verträge, Vorgaben von Ethikkommissionen
- Institutspolitik, Best-Practice Modelle
- Standards in der eigenen Forschungsdisziplin, wie zum Beispiel: CLARIN Standards, PARTHENOS - Standardization Survival Kit (SKK)
-
Wie möchte man die Daten (während des Projekts und vor allem danach) teilen und mit wem (z.B. Fachpublikum, Öffentlichkeit)? Zwei wichtige Prinzipien in diesem Kontext sind:
- FAIR Data: FAIR Data Principles, Go Fair, Jones und Grootveld: “How FAIR are your data?”
- Open Science: Daten sollten nicht nur auffindbar und nachnutzbar, sondern möglichst offen für alle zur Verfügung gestellt werden; siehe dazu: FOSTER Open Science.
Bei Förderanträgen im wissenschaftlichen Bereich wird vermehrt die Vorlage eines Datenmanagementplans gefordert. Durch Beantwortung und eine schriftliche Ausformulierung der obenstehenden Fragen sind die wichtigsten Eckpunkte des Datenmanagementplans bereits gesammelt, denn:
“A data management plan or DMP is a formal document that outlines how data are to be handled both during a research project, and after the project is completed.” (Wikipedia, “Data management plan”)
Diese knappe, aber treffende Definition hebt zwei zentrale Bereiche des Datenmanagements hervor: die Frage nach dem Urheberrecht bzw. der Lizenzierung und die Veröffentlichung bzw. Langzeitarchivierung von Daten nach Projektende. Beim Urheberrecht bzw. der Nutzung von lizenzierten Daten ist vorab zu klären, unter welchen Bedingungen die Daten Dritter im eigenen Projekt verwendet werden dürfen. Beim Aspekt der Veröffentlichung und Archivierung geht es um die im Rahmen des Forschungsprojekts neu gewonnenen Daten und Ergebnisse. Hier sollte man sich Gedanken darüber machen, in welcher Form eine Veröffentlichung der Daten geplant ist und in welcher Form eine Langzeitarchivierung (und somit Zugänglichkeit) der Daten gewährleistet werden kann. Dies bezieht ebenfalls die Frage nach der Vergabe einer geeigneten Lizenz mit ein.
Weiterführende Literatur und Links:
Für weiterführende Informationen, Richtlinien und Beispiele für Datenmanagementpläne sind folgende Seiten empfehlenswert:
- Forschungsdaten.info. “Der Datenmanagementplan.” Universität Konstanz, 2021.
- Trognitz, Martina, Sabine Jahn, Dominik Hagmann und Jörg Räther. “Datenmanagement.” IANUS, 9.11.2016.
- Digital Curation Coalition. “DCC: Data Management Plans.” Digital Curation Centre, 2004-22.
- Science Europe. “Practical Guide to the International Alignment of Research Data Management.” 2022.
- FWF Der Wissenschaftsfonds. “Forschungsdatenmanagement.” Jänner 2022.
- OpenAIRE und EUDAT. ARGOS. 2020.
- Digital Curation Centre. DMPonline. 2010-2022.
C.2. Schritt 2: Daten effizient organisieren und strukturieren
Ein sicherer Ort für die Datenablage ist gefunden, doch dieser allein reicht noch nicht aus. Damit man sich an diesem Ort nicht verläuft und anderen (und auch sich selbst) dabei hilft, bestimmte Daten schnell und auch nach einer (kürzeren oder längeren) Pause die Inhalte rasch und effizient zu finden, verstehen und nutzen zu können, ist es sinnvoll, sich vorab klare Regeln für die Benennung von Dateien und Ordnern und geeignete Ordnerstrukturen zu überlegen. Dieses Kapitel stellt einige leicht umzusetzende Best-Practice Beispiele vor, die einfach auf eigene Forschungsprojekte angewendet werden können.

Abbildung: “Protip: Never look in someone else’s documents folder”, von Randall Munroe, xkcd.com, lizenziert unter CC-BY-NC 2.5.
Viele kennen das Problem einer inkonsistenten Ordner- und Dateibenennung aus dem eigenen Privatleben. Bei der Arbeit und vor allem in einem Team kann dies noch schneller zu Problemen führen. Schon ein paar einfache Maßnahmen können hier zur besseren Strukturierung beitragen.
Gute Datei- und Ordnernamenskonventionen:
- Verwenden Sie eindeutige Namen, die sich klar voneinander unterscheiden (vermeiden Sie zum Beispiel Namen, die sich nur in der Groß- und Kleinschreibung voneinander unterscheiden).
- Verwenden Sie beschreibende Namen, die einen Hinweis auf den Inhalt der Datei, bzw. des Ordners geben.
- Seien Sie bei der Benennung konsistent (ändern Sie Ihr Vorgehen nicht mitten im Projekt).
- Datei- und Ordnernamen sollten so lang wie nötig, aber so kurz wie möglich gehalten werden.
Eine noch bessere Dateibenennung wird ermöglicht durch:
- Angabe des Datums im ISO-Format:
2021-11-01_presentation_datamanagement.pdf - Angabe einer Versionsnummer:
DMP_v1-0.docx;DMP_v2-0.docx;DMP_v2-1.docx - Verwendung einer führenden Null: Die führende Null ist für die automatische Sortierung wichtig. Ohne die führende Null würde auf die 11 die 2 folgen. Zusätzlich hat dies den Effekt, dass Dateinamen auch optisch die gleiche Länge bei allen Bestandsteilen haben. Verwenden Sie keine Punkte in Dateinamen – der Punkt ist reserviert für die Trennung des Dateinamens von der Dateiendung:
.docx;.pdf
Die besten Dateibenennungen können erzielt werden durch die Einhaltung der folgender Regeln:
-
Benutzen Sie keine Leerzeichen, sondern einen Trennstrich (hyphen: data-management) oder einen Unterstrich (underscore: data_management), um Wörter voneinander abzutrennen. Alternativ kann man Wörter auch zusammenschreiben, wofür es mehrere Methoden gibt:
- ohne dabei auf Groß- und Kleinschreibung zu achten (datamanagement)
- oder einen sogenannten “Binnenmajuskel”, also einen Großbuchstaben für jedes neue Wort benutzen (camelCase: dataManagement). Die Nutzung eines Binnenmajuskels erzielt auch eine für den menschlichen Nutzer optisch erkennbare Trennung.
-
Benutzen Sie nur alphanumerische Zeichen, d.h. Zeichen aus dem lateinischen Alphabet und Zahlen. Verzichten Sie auf jegliche Sonderzeichen oder Akzente. Beispiel: Uebergroesse statt Übergröße
-
Verwenden Sie Binde- und Unterstriche, um Elemente im Dateinamen voneinander abzutrennen. Im Datum kann zum Beispiel der Bindestrich für die Trennung von Tag, Monat und Jahr genutzt werden, während der Unterstrich genutzt werden kann, um eine neue Informationseinheit im Dateinamen anzuzeigen:
2021-11-01_presentation_datamanagement.pdf -
Halten Sie die Benennungsregeln für Dateien und Ordner für Ihr Projekt schriftlich fest. Somit haben sowohl Sie selbst als auch Ihr Team diese Regeln immer griffbereit und können diese konsequent und effizient anwenden.
Quiz: Jetzt sind Sie an der Reihe!
Strukturierung und Aufbau von Ordnern
Sobald geeignete Dateibenennungskonventionen für das Projekt festgelegt wurden, folgt im nächsten Schritt die Überlegung, wie die eindeutig und konsequent benannten Dateien nun in Ordner strukturiert werden können. Die 5S-Methode (siehe Fuchs, “How do I use 5S method”) bietet sich hierfür an. Die “5S” stehen hierbei für:
- Sort – zuerst die Ordner und Dateien sichten: alle Dateien darauf kontrollieren, ob überflüssige (z.B. doppelte) Dateien entfernt werden können. Falls man sich nicht sicher ist, ob eine Löschung wirklich durchgeführt werden sollte, kann man einen Ordner “vorgesehenZurLoeschung” oder einen “Dachboden” (attic) für diese Dateien anlegen. In diesem Ordner sollte dann nicht mehr produktiv gearbeitet werden, er dient lediglich der Aufbewahrung vor einer möglichen Löschung. Wenn darin enthaltene Dateien doch noch bearbeitet werden sollen, müssen sie in einen anderen Ordner verschoben werden.
- Set in Order – die gesichteten Ordner und Dateien in eine sinnvolle und für die Arbeit nützliche Reihenfolge bringen. Hierbei ist, wie bei Einzeldateien, wieder auf eine eindeutige und beschreibende Benennung und einheitliche Konventionen zu achten.
- Shine – die Ordner regelmäßig kontrollieren und ggf. aufräumen (also auf Hochglanz polieren, damit sie immer glänzen).
- Standardise – die Regeln für die Strukturierung schriftlich festhalten und die Teammitglieder bzw. Arbeitsgruppe darüber informieren. Es ist wichtig, dass sich bei einer Projektarbeit alle an das festgelegte Regelwerk halten – hierbei hilft eine schriftliche Version enorm (konkrete Hinweise hierzu finden Sie im Abschnitt C.5).
- Sustain – die Ordner- und Datei-Strukturierung pflegen und die Regeln konsequent anwenden. Neue Teammitglieder möglichst rasch mit dem Regelwerk vertraut machen und einschulen. Falls Änderungen notwendig werden, diese immer protokollieren, damit diese nachvollziehbar sind.
Die Wahl der Strukturierung von Ordnern hängt von verschiedenen Faktoren ab und wird von Projekt zu Projekt auch unterschiedlich sein. Einige wichtige Punkte, die hierbei als Strukturierungskriterien herangezogen werden können, sind die folgenden:
- Projekt: um welche Art von Projekt handelt es sich, wie groß ist der Umfang, wie viele Mitglieder gibt es, welche Arbeitspakete gibt es?
- Daten: mit welchen Arten und Typen von Daten wird im Projekt gearbeitet? Welchen Status der Prozessierung von Daten gibt es – hat man zum Beispiel sowohl rohe Messdaten als auch bereinigte Messdaten? Sowohl Datentyp als auch Datenverarbeitungszustand können als Strukturierungselemente verwendet werden.
- Aktivitäten: können Arbeitspakete als Strukturierungselemente dienen oder wird mit unterschiedlichen Methoden an den Daten gearbeitet, die man voneinander trennen kann oder sogar sollte?
- Dokumentation und administrative Dateien: diese Dateien sind wichtig, um Regeln, Richtlinien und administrative Abläufe festzuhalten und sollten getrennt aufbewahrt werden.
- Externe Richtlinien: gibt es für die Forschungsrichtung oder das Projekt spezielle Richtlinien, die befolgt werden müssen und daher zum Nachschlagen verfügbar sein sollten? Für ein Forschungsprojekt in der Archäologie ist in Österreich zum Beispiel die Vorgabe des Bundesdenkmalamts relevant.
Außerdem sollte man beim Festlegen der Ordnerstruktur vorab überlegen, wie die Hierarchie der Ordner aufgebaut sein soll: Eignet sich eher eine flache oder eine tiefe Ordnerstruktur? Wie bei der Dateibenennung sollten für die Ordner aussagekräftige, verständliche Namen gewählt werden und die oben bereits erläuterten Best-Practice Techniken eingehalten werden. Auch die Ordnerstruktur selbst sollte möglichst logisch und selbsterklärend gewählt werden.
Wichtig ist auch, eine Duplizierung von Dateien zu vermeiden, da bei eventuell notwendigen Änderungen die Gefahr von Inkonsistenzen besteht. Ebenso sollten Verknüpfungen von einer Datei oder einem Ordner auf eine(n) andere(n) vermieden werden. Denn sollte sich der Speicherort von verknüpften Dateien oder Ordnern ändern, so wird auch die Verlinkung ins Leere führen.
Weiterführende Literatur und Links:
Für ausführlichere Informationen zur Benennung und Strukturierung von Dateien und Ordnern sowie zur Versionierung empfehlen wir folgenden Seiten:
- CESSDA Training. “Data Management Expert Guide.” CESSDA ERIC, 2017-2020.
- Fuchs, Siiri: “How do I use 5S method for organizing data files?” In: Think Open Blog. Helsinki, 2019.
- Trognitz, Martina, Felix Schäfer, Reiner Göldner, und Thomas Schenk. “Dateiverwaltung.” IANUS, 18.11.2017.
- Stanford Libraries. “Data Best Practices and Case Studies.” Stanford University, 2022.
C.3. Schritt 3: Arbeiten mit Versionierung
Gerade beim gemeinschaftlichen Arbeiten ist die Versionierung von Dateien und Ordnern relevant. Durch die Speicherung und Kennzeichnung von Versionen können Änderungen einfach nachverfolgt werden und man kann leicht zu früheren Bearbeitungsstufen von Daten und Dateien zurückkehren. Um einen manuellen Abgleich der Dokumente auf die konkreten Unterschiede zu vermeiden, ist es ratsam, die Versionsänderungen in einem eigenen Protokoll oder Textdokument zu dokumentieren. Bei umfangreichen Projekten bietet sich die Nutzung dedizierter Versionierungssoftware an.
Wie kann Versionierung durchgeführt und verwaltet werden?
Eine manuelle Versionierung bietet sich vor allem an, wenn Sie alleine an einem Projekt und dessen Dateien und Ordnern arbeiten. Bei einer manuellen Durchführung der Versionierung kann die Version im Dateinamen mit folgenden Elementen festgehalten werden: Datum, Versionsnummer oder beschreibende Hinweise (Marker) wie “draft” oder “final”. Eine Kombination der Elemente kann ebenfalls sinnvoll sein.
Zusätzlich zur Dateibenennung sollte entweder in der Datei selbst festgehalten werden, wann und von wem welche Änderung durchgeführt wurde. Diese Änderungen können aber auch in einer separaten gespeicherten Datei (dem Protokoll oder changelog) dokumentiert werden.
Wenn mehrere Personen an einem Projekt mit vielen Daten arbeiten, kann eine Software für die Versionierung genutzt werden. Diese zeichnet automatisch Änderungen nach und speichert die unterschiedlichen Dateiversionen ab. Einfache Versionierungen sind zum Beispiel mit Google Drive, Nextcloud oder ownCloud möglich; für komplexere Projekte bieten sich Dienste wie Git an.
Was macht eine neue Version aus? Hier bietet sich die semantische Versionierung als Methode an, welche aus dem Bereich der Softwareprogrammierung kommt (siehe: semver). Es gibt eine Adaption für die Arbeit an Textdokumenten (siehe: semverdoc). Sie beschreibt, wie Versionsnummern und -benennung sinnvoll gewählt und angewendet werden:
Eine semantische Versionierung würde zum Beispiel so aussehen:
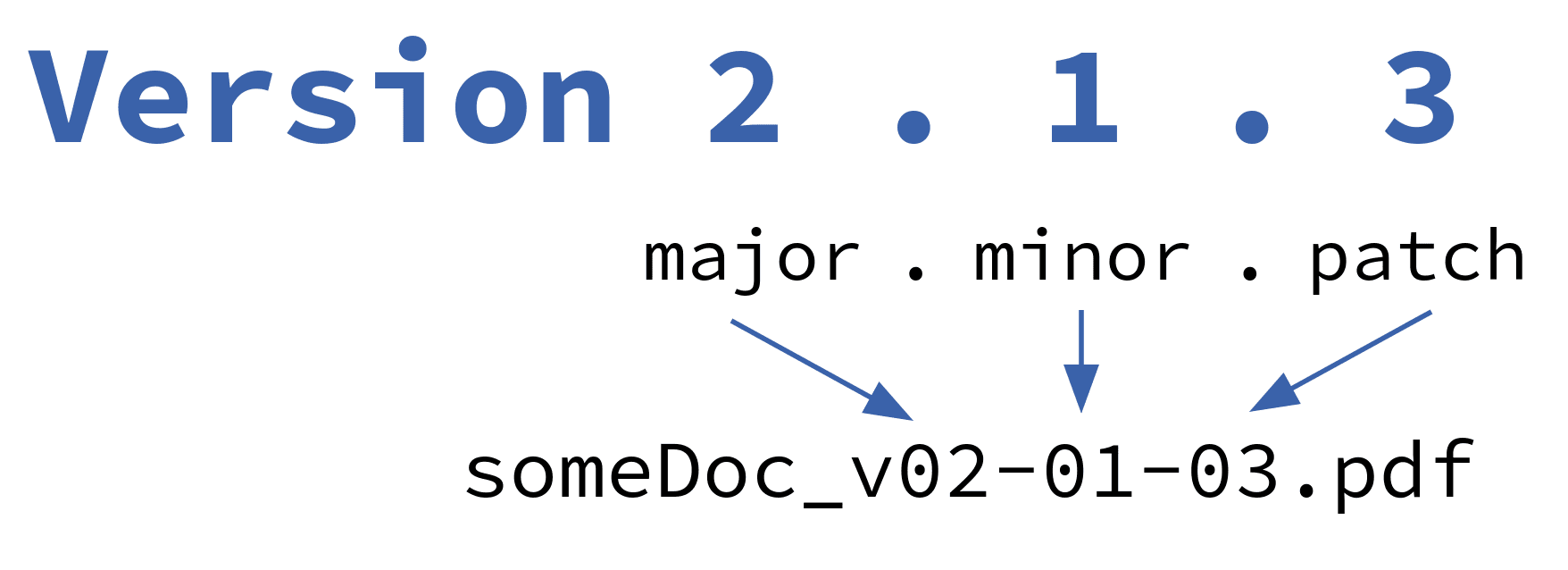
Abbildung: Versionierungselemente, von Martina Trognitz, lizenziert unter CC-BY 4.0.
- Major: wird für signifikante Änderungen vergeben
- Minor: wenige Informationen verändert oder hinzugefügt
- Patch: kleinere Fehlerkorrektur, zum Beispiel Ausbesserung eines Tippfehlers
Quiz:
Weiterführende Literatur und Links:
- (semver) - Preston-Werner, Tom: “Semantic Versioning 2.0.0.”
- (semverdoc) - Tekampe, Nils: “Semantic Versioning for Documents and Meaningful Manual Version Control.”
- Stanford Libraries. “Version Files.” Data Best Practices and Case Studies. Standford University, 2022.
- Trognitz, Martina. “Versionskontrolle.” IANUS, 18.11.2017.
Nützliche Tools:
C.4. Schritt 4: Die Wahl des richtigen Dateiformats
Bei der Arbeit mit Forschungspartner*innen von anderen Institutionen oder aus anderen Ländern und auch im Hinblick auf eine spätere Langzeitarchivierung ist es notwendig, sich vorab zu einigen, welche Dateiformate für die Speicherung sinnvoll sind und genutzt werden sollen. Ein paar einfache Prinzipien helfen bei der Auswahl des Dateiformats.
Die wichtigste Regel ist, dass das Dateiformat möglichst breit in Verwendung sein sollte. Man wählt am besten ein Format, das nicht proprietär ist. Bei Textdateien würde man daher OpenDocument-Dateien (odt) Vorrang vor Word-Dokumenten (docx) geben, denn während das OpenDocument-Format sowohl von Word als auch von OpenSource-Software lesbar ist, können einige Word-Features nicht von anderen Textverarbeitungsprogrammen dargestellt werden.
Wenn möglich, sollten Dateiformate mit offenen Standards (Open Standard) genutzt werden. Hierbei sind die Formatspezifikationen einsehbar und Programmierer*innen können bei Bedarf einen Code entwickeln, um damit formatierte Dateien einzusehen.
Dateien sollten auch nicht komprimiert (zum Beispiel .zip oder .jpeg) werden oder nur eine verlustfreie Kompression verwenden. Dateien sind auch unverschlüsselt, also ohne Passwortschutz zu speichern, da sie sonst nicht von anderen geöffnet werden können.
Sie sollten sich auch vorab mit den Standards und Anforderungen in Ihrem Fachbereich auseinandersetzen. Bringen Sie bereits zu Beginn des Projekts in Erfahrung, welche Vorgaben Ihre Fördergeber*innen und die gängigen Archive in Ihrem Forschungsgebiet für die Langzeitarchivierung machen und halten Sie sich an diese Richtlinien.
ARCHE (A Resource Centre for the Humanities), ein Service des ACDH-CH (Austrian Centre for Digital Humanities and Cultural Heritage) für die Langzeitarchivierung digitaler Forschungsdaten und -services bevorzugt beispielsweise folgende Dateiformate:
-
Formatierter Text: PDF/A-1, PDF/A-2
- anstatt von: PDF, docx, doc
-
Strukturierter Text: xml, html, txt, md, text (UTF-8, no BOM);
- anstatt von: PDF, docx, doc, odt, indd
-
Plain (reiner) Text: txt (UTF-8, no BOM)
- anstatt von: PDF, docx, odt
-
Bilder: tiff, dng
- anstatt von: jpeg, psd, gif
-
Vektorgrafiken: svg
- anstatt von: ai, indd, ps, dwg, dxf
-
Tabellen: csv (UTF-8, no BOM)
- anstatt von: xlsx, xls, ods
Weitere Hinweise zu Textdokumenten und deren möglichen Formaten:
Wenn die langfristige Erhaltung der optischen Darstellung eines Textdokumentes im Vordergrund steht, sollte ein geeignetes Format für formatierten Text, wie PDF/A gewählt werden. Steht jedoch die Bearbeitbarkeit und vor allem die Erhaltung der Strukturierung im Vordergrund, sollte ein entsprechend geeignetes Format, wie etwa TEI/XML verwendet werden.
Wann immer eine Zeichenkodierung für ein Format wählbar ist, sollte UTF-8 ohne BOM (Unicode) gewählt werden. Unicode ist ein Standard, der zum einen beschreibt, wie Schrift elektronisch gespeichert wird und zum anderen einen umfangreichen Zeichensatz zur Darstellung von Schriftzeichen aus über 150 Sprachen bereitstellt. Im Gegensatz dazu kann ASCII lediglich 256 Zeichen kodieren, was bei Texten mit Umlauten oder Zeichen aus anderen Sprachen schon nicht mehr ausreicht. Üblicherweise kann die Zeichenkodierung für alle rein textbasierten Formate wie csv, txt, oder auch xml gewählt werden.
Weiterführende Literatur und Links:
- Austrian Centre for Digital Humanities and Cultural Heritage. ARCHE - A Resource Centre for the Digital Humanities. 2020.
- Trognitz, Martina. “Textdokumente.” IANUS, 4.4.2016.
- The Unicode Consortium. Unicode. 1991-2021.
C.5. Schritt 5: Die schriftliche Dokumentation
Für ein konsistentes Datenmanagement ist eine schriftliche Dokumentation von zentraler Bedeutung. Dies gilt insbesondere für die Zusammenarbeit mit anderen Personen, Forschungseinrichtungen und externen Dienstleistern. Auch mit Hinblick auf Vorgaben von Fördergeber*innen und Archiven ist eine schriftliche Dokumentation hilfreich und erleichtert die Arbeit enorm.
Die schriftliche Dokumentation sollte Aufschluss darüber geben, wie gearbeitet wird bzw. wurde und in welchen Schritten die Bearbeitung der Daten erfolgte (wer, wann und was wurde geändert). Folgende Fragen sollte die Dokumentation daher klar beantworten können:
- Wie sind die Daten strukturiert?
- Wer ist wofür zuständig?
- Welche Dateibenennungsregeln wurden im Projekt angewendet und welche Richtlinien liegen der Ordnerstrukturierung zugrunde?
- Wie wurde die Versionierung vorgenommen?
Am einfachsten ist es, die Dokumentation in einer Readme-Datei festzuhalten. Dies kann in einer einfachen Textdatei (txt) oder im Markdown-Format (md) erfolgen. Markdown hat den Vorteil, dass die spezielle Syntax eine Strukturierung erlaubt, die mit entsprechenden Programmen auch optisch dargestellt werden kann, dazu gehören zum Beispiel Überschriften, Links oder auch Listen. (siehe: CommonMark, GitHub Flavored Markdown Spec.
Ein strukturierterer Weg um Daten zu beschreiben, der auch eine maschinelle Lesbarkeit ermöglicht, sind Metadaten. Hierbei können verschiedene Metadatenschemata, wie etwa Dublin Core zur Anwendung kommen.
Weiterführende Literatur und Links:
- MacFarlane, John, Martin Woodward, and Jeff Atwood. CommonMark. 2014-2022.
- GitHub Flavored Markdown Spec. Version 0.29-gfm, 06.04.2019.
- Dublin Core Metadata Initiative. Dublin Core. 1995-2022.